Socio-géographie électorale de Paris intra-muros lors des élections présidentielles 2017
Cette page reprend l'ensemble de ma démarche méthodologique pour la réalisation de mon mémoire.
Organisation
Les données sont disponibles dans la section Raw_data de ce repositorie tandis que les cartes produites sont dans Maps.
Obtention des données
Données électorales
Les données brutes que j’ai utilisées proviennent d’OpenData, mais ont été retravaillées par @Aktiur. Les données exploitées sont les données en Large.
Données sociologiques
Celles-ci proviennent du site de l’INSEE,
Traitement des données
L’ensemble des traitements statistiques est réalisé grâce à RStudio.
Réalisation d’une carte intéractive pour avoir les deux geoJson des bureaux 2012 et 2017 superposés. J’ai ainsi pu rajouter manuellement l’identifiant de chaque bureau de 2012 dans 2017. Lors de cette étape j’ai du faire certains choix qui ont présenté le principal biais pour la suite du travail, à savoir que certains bureaux ne se superposaient pas complètement, ou plusieurs bureaux de 2017 étaient repris dans un seul bureau de 2012. (860 bureaux sur 890 contiennent de l’information sociologiques, il n’y a pas de problème pour les données électorales)
Production de cartes thématiques gréduées par candidats
Pour la production de cartes électorales, j’ai utilisé le fichierR_P_L_2 qui a été construit comme suit:
R_P_L_1 = X2017_presidentielle_1_par_bureau_large [ which (X2017_presidentielle_1_par_bureau_large$departement == '75'), ] # Keep only departement 75 (Paris)
write.csv(R_P_L_1, "R_P_L_1.csv") # Extract as csv
# le code que me donne l'outil import dataset et la modiciation de chaque colonne en character ainsi que la suprresion des superflues
R_P_L_1 <- read_csv("~/Desktop/données/R_P_L_1.csv", # Import RPL1 as charachter and delete unused column
+ col_types = cols(ARTHAUD = col_character(),
+ ASSELINEAU = col_character(), CHEMINADE = col_character(),
+ `DUPONT-AIGNAN` = col_character(),
+ FILLON = col_character(), HAMON = col_character(),
+ LASSALLE = col_character(), `LE PEN` = col_character(),
+ MACRON = col_character(), MÉLENCHON = col_character(),
+ POUTOU = col_character(), X1 = col_skip(),
+ blancs = col_character(), circonscription = col_skip(),
+ commune = col_skip(), commune_libelle = col_skip(),
+ departement = col_skip(), exprimes = col_character(),
+ inscrits = col_character(), votants = col_character()))
write.csv(R_P_L_1, "R_P_L_2.csv") # Extract as csv
Voici donc le tableau final utilisé :
| bureau | inscrits | votants | blancs | exprimes | ARTHAUD | ASSELINEAU | CHEMINADE | DUPONT-AIGNAN | FILLON | HAMON | LASSALLE | LE PEN | MACRON | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0101 | 1079 | 926 | 6 | 914 | 3 | 10 | 3 | 17 | 295 | 62 | 3 | 49 | 348 |
| 2 | 0102 | 1172 | 991 | 11 | 978 | 3 | 3 | 3 | 2 | 254 | 83 | 6 | 43 | 424 |
| 3 | 0103 | 1155 | 957 | 9 | 947 | 0 | 13 | 0 | 17 | 210 | 77 | 12 | 56 | 409 |
| 4 | 0104 | 1300 | 1069 | 14 | 1052 | 0 | 10 | 2 | 19 | 226 | 102 | 9 | 57 | 381 |
Bien entendu ce n’est qu’un extrait (voir raw_data du repo)
J’utilise donc bureaux_clean_shp_IDavec un de mes trois fichier crées au dessus (R_P_L_2_PI, R_P_L_2_PE, R_P_L_2_PV). Il me reste donc à choisir quel fichier de résulats je vais exploiter et quels discrétisation je souhaite utiliser.
Les résultats ne sont pas encore en pourcent:
Poucentages_inscrits = R_P_L_2 # work on a new dataset
colnames(Poucentages_inscrits) # rename data with false name
# [1] "bureau" "inscrits" "votants" "blancs" "exprimes" "ARTHAUD" "ASSELINEAU" "CHEMINADE" "DUPONT-AIGNAN"
# [10] "FILLON" "HAMON" "LASSALLE" "LE PEN" "MACRON" "MÉLENCHON" "POUTOU"
names(Poucentages_inscrits)[names(Poucentages_inscrits) == "DUPONT-AIGNAN"] <- "DUPONTAIGNAN"
names(Poucentages_inscrits)[names(Poucentages_inscrits) == "LE PEN"] <- "LEPEN"
names(Poucentages_inscrits)[names(Poucentages_inscrits) == "MÉLENCHON"] <- "MELENCHON"
# Create new column for each candidate in percentage
Poucentages_inscrits$PARTHAUD = ((Poucentages_inscrits$ARTHAUD/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PASSELINEAU = ((Poucentages_inscrits$ASSELINEAU/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PCHEMINADE = ((Poucentages_inscrits$CHEMINADE/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PDUPONTAIGNAN = ((Poucentages_inscrits$DUPONTAIGNAN/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PFILLON = ((Poucentages_inscrits$FILLON/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PHAMON = ((Poucentages_inscrits$HAMON/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PLASSALLE = ((Poucentages_inscrits$LASSALLE/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PLEPEN = ((Poucentages_inscrits$LEPEN/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PMACRON = ((Poucentages_inscrits$MACRON/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PMELENCHON = ((Poucentages_inscrits$MELENCHON/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits$PPOUTOU = ((Poucentages_inscrits$POUTOU/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits[2:16] <- list(NULL) # remove old column
write.csv(Poucentages_inscrits, "R_P_L_2_PI.csv") # extract in csv
Pour les cartes graduées j’utilise donc bureaux_clean_shp_ID en jointure avec R_P_L_2_PI qui sont les résultats en pourcentage des inscrits pour rendre compte de l’abstention.
Un problème de correspondance survient lors de la jointure. Après quelque temps de blocage, je me suis concentré sur la colonne id_bv de mon shapefile des bureaux de vote qui étaient de type xx-xx (voir première table), alors que mes ID bureau de R_P_L_1 sont de type xxxx (voir seconde table).
| OBJECTID | Nombre d’électeurs Français à cette adresse | Nombre d’électeurs européens pour les élections Municipales | Nombre d’électeurs européens pour les élections Européennes | Nombre d’électeurs à l’étranger | Validité | N° arrondissement | N° Bureau de vote | Identifiant du bureau de vote |
|---|---|---|---|---|---|---|---|---|
| 4 | 1267 | 14 | 12 | 0 | oui | 19 | 5 | 19-5 |
| 5 | 1331 | 6 | 6 | 0 | oui | 19 | 7 | 19-7 |
| 9 | 1454 | 23 | 20 | 0 | oui | 19 | 14 | 19-14 |
| 10 | 1400 | 29 | 25 | 0 | oui | 19 | 10 | 19-10 |
| departement | commune | bureau | circonscription | commune_libelle | inscrits | votants | blancs | exprimes | ARTHAUD | ASSELINEAU | CHEMINADE | DUPONT-AIGNAN | FILLON | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 75 | 056 | 0101 | 1 | Paris | 1079 | 926 | 6 | 914 | 3 | 10 | 3 | 17 | 295 |
| 2 | 75 | 056 | 0102 | 1 | Paris | 1172 | 991 | 11 | 978 | 3 | 3 | 3 | 2 | 254 |
| 3 | 75 | 056 | 0103 | 1 | Paris | 1155 | 957 | 9 | 947 | 0 | 13 | 0 | 17 | 210 |
| 4 | 75 | 056 | 0104 | 1 | Paris | 1300 | 1069 | 14 | 1052 | 0 | 10 | 2 | 19 | 226 |
Via la calculatrice de champs de QGIS j’ai pu modifié le hyphen à savoir "-"de la colonne id_bv, ce que j’ai mis en entrée est dans l’image ci-dessous :
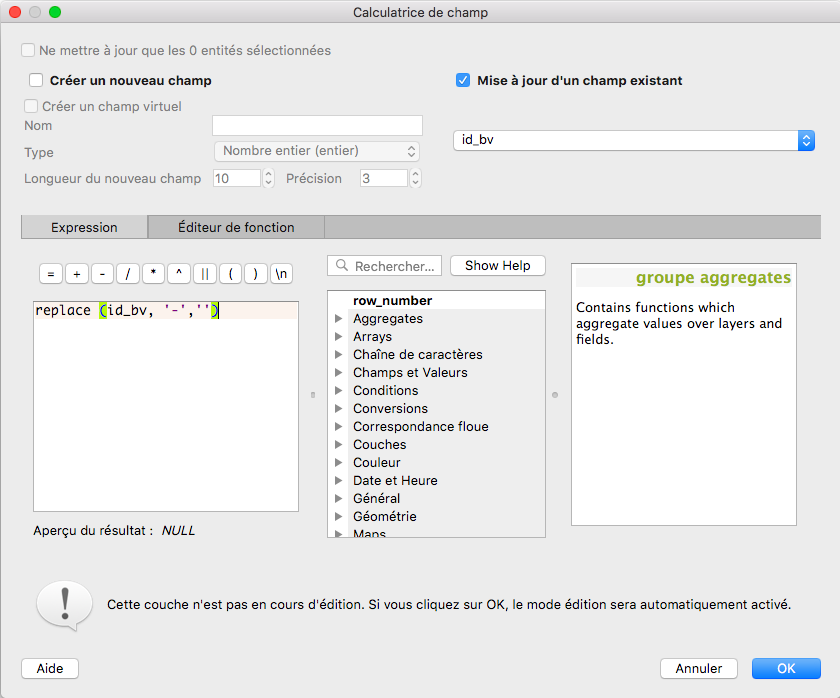
Ensuite j’ai dû réaliser à la main, la modification de chaque ID pour le faire correspondre. les 1-1 étant devenus 11 devaient être modifiés en 0101 par exemple. J’ai procédé petit à petit en vérifiant en parallèle que ma jointure concordait. La table que j’en ai tiré, je l’extrais en un nouveau shapefile bureaux_clean_shp.shp. (D’ailleurs, il est assez perturbant de ne plus trouver dans QGIS3 la fonction save as comme sur les versions précédentes, j’ai eu réponse à ma question ici)
Ce shapefile est simplement l’ensemble des contours de Paris (voir ci-dessous), sauf qu’à présent j’ai de quoi le lier à mes résultats des élections.
Carte des résultats du second tour :
J’ai dû à nouveau traiter les données pour obtenir des données exploitables dans QGIS, j’ai modifié mon script R :
R_P_L_T2_1 = X2017_presidentielle_2_par_bureau_large [which(X2017_presidentielle_2_par_bureau_large$departement== '75'), ] # keep only department 75 (Paris)
Poucentages_inscrits = R_P_L_T2_1 # work on a new dataset
colnames(Poucentages_inscrits) # rename data with false name
#[1] "departement" "commune" "bureau" "circonscription" "commune_libelle"
#[6] "inscrits" "votants" "blancs" "exprimes" "LE PEN"
#[11] "MACRON"
Poucentages_inscrits[1:2] = list(NULL) # remove col departement commune cicronscription
Poucentages_inscrits[2:3] = list(NULL)
names(Poucentages_inscrits)[names(Poucentages_inscrits) == "LE PEN"] <- "LEPEN" # rename the wrong names
Poucentages_inscrits$PLEPEN = ((Poucentages_inscrits$LEPEN/Poucentages_inscrits$inscrits)*100) # Create new column for each candidate in percentage
Poucentages_inscrits$PMACRON = ((Poucentages_inscrits$MACRON/Poucentages_inscrits$inscrits)*100)
Poucentages_inscrits[6:7] = list(NULL) # remove old column
write.csv(Poucentages_inscrits, "R_P_L_T2_2.csv") # extract in csv
Ensuite j’ai effectué la jointure déjà expliquée précédemment pour obtenir des cartes avec rupture de Jenks à 6 classes pour
Discrétisation
Lors de la création de cartes, il faut bien choisir ses classes et les bons modes de discrétisation. Je me suis basé sur le lien précédent pour la compréhension de ce principe.
“La discrétisation est l’opération qui permet de découper en classes une série de variables qualitatives ou de variables quantitatives. Cette opération simplifie l’information en regroupant les objets géographiques présentant les mêmes caractéristiques en classes distinctes.” Cette définition provient d’Hypergéo.
Dans QGIS il existe 5 mode de discrétisation qui répondent à certaines règles :
Règles
- les classes doivent couvrir l’ensemble des données
- il faut éviter les classes vides
- il faut déterminer la forme principale de la distribution
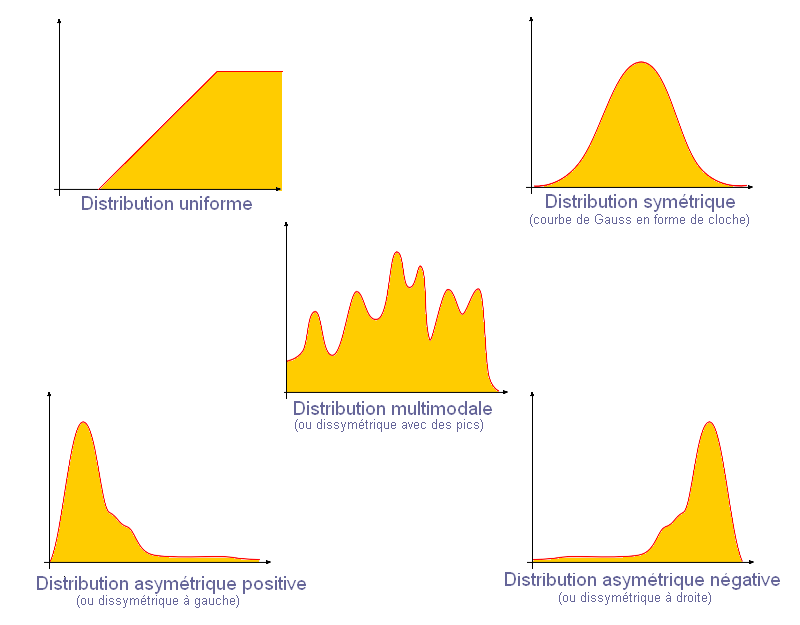
Les modes et utilisation
- intervalles égaux : amplitude entre les valeurs min et max est divisée par le nombre de classes
==> distribution uniforme ou symétrique.
Autrement dit les valeurs des données sont réparties uniformément sur toute l’amplitude de la série. Ce mode n’est pas adapté si les valeurs extrêmes s’écartent de la série.
- quantiles (effectifs égaux) : chaque classe répresente même nombre de données soit 1/n de l’effectif des données (n étant le nombre de classes)
==> toutes les formes de distribution (à utiliser quand distribution uniforme ou multimodale).
Il implique une répartition équilibrée des données.
- Ruptures naturelles (Jenks) : Minimisation des variances intra-classes. Pour chaque classes les valeurs sont les plus proches (tendance homogène) et les classes sont les plus éloignées possibles (tendance hétérogène)
Proche des seuils observés, donne généralement de bons résultats pour toutes les distributions (à utiliser avec multimodale) mais n’est pas conseillée malgré tout lorsque la distribution est trop hétérogène.
- Ecart-type (std dev) : chaque classe est déterminée selon un fraction ou un multiple de l’écart-type par rapport à la moyenne. L’écart-type mesure la dispersion d’une série de valeurs autour de leur moyenne (ici toutes les valeurs)
==> distribution symétrique, Gauss (à utiliser avec une distribution symétrique ou très peu dissymétrique)
- Jolies ruptures : liée à la fonction pretty de R, permet d’obtenir des intervalles de classe équidistants arrondis (jolies valeurs) et couvrant l’ensemble des valeurs.
Se rapproche des intervalles égaux, avec classes adaptées aux extrémités de la distribution (à utiliser pour distribution uniforme ou symétrique)
- pour distribution asymétrique à gauche : progression géométrique qui est pas dans Qgis, donc on va utiliser des modes pour multimodale (quantile ou Jenks) ou utiliser la colonne expression pour transformer l’échelle de la valeur à discrétiser. (on va utiliser fonction log ou carrée)
Un petit récapitulatif : Mode Cheatsheet.
Ventilation
Afin de mettre en commun mes données sociologiques et électorales je devais obtenir un ID correspondant entre les résultats par bureaux de 2012 et ceux de 2017. En effet les premiers contiennent l’identifiant IRIS qui permet de les lier aux données sociologiques pour la ventilation.
Pour cela j’ai réalisé une carte intéractive qui me permet de visualiser les deux GeoJson de manière simultanée, et en parallèle j’utilisais la table de mes bureaux de 2017 dans QGIS. Cela m’a permis d’ajouter manuellement un ID de 2012 pour chaque bureau de 2017. Cette étape s’est avérée très longue et aurait pu être automatisée, seulement le niveau demandé pour cette étape était plus élevé que mes compétences.
Script pour la carte interactive:
# required Packages
library(rgdal)
library(sf)
library(mapview)
# Processing
bureaux_clean_ID_geojson <- readOGR(dsn = "./data_raw/bureaux_clean_ID.geojson", layer = "OGRGeoJSON") # read geojson
psgjsn <- ParisPollingStations2012 # Data I want to add as layer
bgjsn <- bureaux_clean_ID_geojson # Data I want to add as layer
# Visualization
mapview(
bgjsn,
map.types = "CartoDB",
col.regions = "red",
label = bgjsn$geometry,
alpha.regions= 0,
color = "red",
legend = TRUE,
layer.name = "2017",
homebutton = FALSE,
lwd = 2
) +
mapview(
psgjsn,
map.types = "CartoDB",
col.regions = "black",
label = psgjsn$geometry,
alpha.regions= 0,
color = "black",
legend = TRUE,
layer.name = "2012",
homebutton = FALSE,
lwd = 2
)+
mapview(
arrondissements,
map.types = "CartoDB",
col.regions = "green",
label = psgjsn$geometry,
alpha.regions= 0,
color = "green",
legend = TRUE,
layer.name = "arrondissements",
homebutton = FALSE,
lwd = 5
)
Après avoir ajouté ce nouvel ID dans mes bureaux de 2017 je suis à même de les joindre avec les bureaux de 2012. Ce nouveau fichier s’appelle bureaux_avec_ID_PS_2012.geojson. Grâce à celui j’ai donc la possibilité de joindre mes résultats électoraux de 2017 aux bureaux de 2012 et donc aux données sociologiques. En effet grâce au package SpReapportion de @joelgombin, j’ai la possibilité de ventiler les données sociologiques, qui sont à l’échelle IRIS à l’intérieur des bureaux électoraux de 2012. Autrement dit, les données reprises dans une entité à l’échelle IRIS sont considérées comme uniforme sur cette entité et sont ensuite transférées au sein d’une entité à l’échelle des bureaux de 2012.
Ensuite, j’ai effectué la jointure des bureaux de 2017 sur le résultat de la ventilation, puis j’ai joint les résultats électoraux ce qui me donne comme fichier final CS_ag_resultats2017.csv. Le script de cette étape:
##### required packages #####
install.packages("sp")
install.packages("sf")
install.packages("mapview")
install.packages("devtools")
install.packages("rgdal")
install.packages("dplyr")
devtools::install_github("joelgombin/spReapportion")
library(sp)
library(sf)
library(mapview)
library(devtools)
library(rgdal)
library(spReapportion)
library(dplyr)
##### Open the data #####
load("~/Documents/MA2/Mémoire/jointure/data_raw/ParisIris.rda")
load("~/Documents/MA2/Mémoire/jointure/data_raw/ParisPollingStations2012.rda")
load("~/Documents/MA2/Mémoire/jointure/data_raw/RP_2011_CS8_Paris.rda")
iriscleanagepop <- read_csv("~/Documents/MA2/Mémoire/jointure/data_raw/IRIS_CLEAN_age_pop.csv",
col_types = cols(X1 = col_skip()))
bureaux_ID_PS <- readOGR(dsn = "./data_raw/bureaux_avec_ID_PS_2012.geojson", layer = "OGRGeoJSON")
R_P_L_2_PI <- read_csv("~/Documents/MA2/Mémoire/jointure/data_raw/R_P_L_2_PI.csv",
col_types = cols(X1 = col_skip(), bureau = col_double()))
##### Process data #####
new_IRIS = merge(RP_2011_CS8_Paris, iriscleanagepop) # Merge CS and age
new_IRIS = new_IRIS %>% # Keep only âge
select(1,13:23)
catégories_sociales_bureaux2012 = spReapportion(ParisIris, ParisPollingStations2012, RP_2011_CS8_Paris, "DCOMIRIS", "ID", "IRIS") # the reaportion with spReaportion from https://github.com/joelgombin/spReapportion made by Joël Gombin
age_bureaux2012 = spReapportion(ParisIris, ParisPollingStations2012, new_IRIS, "DCOMIRIS", "ID", "IRIS")
##### create newdata #####
ps2012 = ParisPollingStations2012
ps2017 = bureaux_ID_PS
CS2012 = catégories_sociales_bureaux2012
age2012 = age_bureaux2012
ps2012_sf = sf ::st_as_sf(ps2012) # need as sf for the following
##### Join the census data and the social data #####
names(ps2017)[names(ps2017) == "nouvel_ID"] <- "ID" # rename col to have the same for the joining
ps2012_2017_sf = merge(x = ps2012_sf, y = ps2017, by = "ID", all.x = TRUE) # merge ParisPollingStations2012 with ParisPollingStations2017
CS_2012_2017 = merge(x = CS2012, y = ps2012_2017_sf, by = "ID", all.x = TRUE) # merge Parispollingstations2012-2017 with sociological data
final_data = merge(x = CS_2012_2017, y = age2012, by = "ID", all.x = TRUE) # Add the age data
##### Clean Data #####
final_data_clean = final_data %>%
select(2:10,23,27:37)
final_data_clean = final_data_clean[,c(10,1:9,11:21)] # set id_bv as first column
names(final_data_clean)[names(final_data_clean) == "id_bv"] = "bureau" # rename id_bv as bureau
CS_age_resultats2017 = merge(x = final_data_clean, y = R_P_L_2_PI, by = "bureau", all.x = TRUE) # merge CS with results
CS_age_resultats2017 = CS_age_resultats2017[-c(881:894), ] # Delete rows where bureau doesn't exist
CS_age_resultats2017 = CS_age_resultats2017 %>% # convert CS to percentile
mutate_at(vars( C11_POP15P_CS1 :C11_POP15P_CS8), funs(. / C11_POP15P * 100)
)
CS_age_resultats2017 = CS_age_resultats2017 %>% # convert age to percentile
mutate_at(vars(POP02:POP80P), funs(. / POP * 100)
)
##### Export #####
write.csv(CS_age_resultats2017, "CS_age_resultats_2017")
Script pour toutes les régressions linéaires multiples:
Pour vérifier la véracité des cartes j’ai réalisé une série de régressions linéaires mutliples (les données indépendantes ont été sélectionnées sur base de la méthode de stepwise regression):
##### required packages #####
library(broom)
library(car)
library(dplyr)
library(ggplot2)
library(readr)
library(tidyverse)
##### Open data #####
CS_age_resultats_2017_centralite <- read_csv("~/Documents/MA2/Mémoire/all_regressions/data_raw/CS_age_resultats_2017_centralite.csv",
col_types = cols(C11_POP15P = col_skip(),
X1 = col_skip()))
##### Clean data #####
temp_cs = CS_age_resultats_2017_centralite # Work on a temporary dataset
temp_cs = temp_cs %>%
rename( CS1 = C11_POP15P_CS1,
CS2 = C11_POP15P_CS2,
CS3 = C11_POP15P_CS3,
CS4 = C11_POP15P_CS4,
CS5 = C11_POP15P_CS5,
CS6 = C11_POP15P_CS6,
CS7 = C11_POP15P_CS7,
CS8 = C11_POP15P_CS8,
"18-24 ans" = POP1824,
"25-39 ans" = POP2539,
"40-54 ans" = POP4054,
"55-64 ans" = POP5564,
"65-79 ans" = POP6579,
"80 ans" = POP80P,
Arthaud = PARTHAUD ,
Asselineau = PASSELINEAU ,
Cheminade = PCHEMINADE ,
Dupont_Aignan = PDUPONTAIGNAN ,
Fillon = PFILLON ,
Hamon = PHAMON ,
Lassalle = PLASSALLE ,
Lepen = PLEPEN ,
Macron = PMACRON ,
Melenchon = PMELENCHON ,
Poutou = PPOUTOU
)
######
table_cor = round(cor(temp_cs[17:27]), 2) # correlation table to see all correllations between all variables
write.csv(table_cor, "tablecor_cs_age.csv")
# Arthaud
Arthaud_CS = lm(temp_cs$Arthaud ~ temp_cs$CS2 + temp_cs$CS4 + temp_cs$CS5 +temp_cs$CS6 + temp_cs$CS7 + temp_cs$CS8 + temp_cs$distance, data=temp_cs)
summary(Arthaud_CS) # show results
tidyArthaud = tidy (summary(Arthaud_CS))
write.csv(tidyArthaud, "Arthaud.csv")
# Asselineau
Asselineau_CS = lm(temp_cs$Asselineau ~ temp_cs$CS4 + temp_cs$CS5 +temp_cs$CS6 + temp_cs$CS7 + temp_cs$`18-24 ans` + temp_cs$`25-39 ans` + temp_cs$`40-54 ans` + temp_cs$`55-64 ans`, data=temp_cs)
summary(Asselineau_CS) # show results
tidyAsselineau = tidy (summary(Asselineau_CS))
write.csv(tidyAsselineau, "Asselineau.csv")
# Cheminade
Cheminade_CS = lm(temp_cs$Cheminade ~ temp_cs$CS1 + temp_cs$CS2 + temp_cs$CS4 + temp_cs$CS5 + temp_cs$CS7 + temp_cs$CS8 +temp_cs$distance, data=temp_cs)
summary(Cheminade_CS) # show results
tidyCheminade = tidy (summary(Cheminade_CS))
write.csv(tidyCheminade, "Cheminade.csv")
# Dupont-Aignan
Dupont_Aignan_CS = lm(temp_cs$Dupont_Aignan ~ temp_cs$CS2 + temp_cs$CS4 +temp_cs$CS6 + temp_cs$CS7 + temp_cs$distance, data=temp_cs)
summary(Dupont_Aignan_CS)
tidyDupont = tidy (summary(Dupont_Aignan_CS))
write.csv(tidyDupont, "Dupont.csv")
# Fillon
Fillon_CS = lm(temp_cs$Fillon ~ temp_cs$CS2 + temp_cs$CS3 + temp_cs$CS4 + temp_cs$`55-64 ans` + temp_cs$`65-79 ans` + temp_cs$`80 ans` + temp_cs$distance, data=temp_cs)
summary(Fillon_CS)
tidyFillon = tidy (summary(Fillon_CS))
write.csv(tidyFillon, "Fillon.csv")
temp_cs$residusFI = resid(Fillon_CS)
# Hamon
Hamon_CS = lm(temp_cs$Hamon ~ temp_cs$CS2 + temp_cs$CS4 + temp_cs$CS6 + temp_cs$CS7 + temp_cs$`18-24 ans` + temp_cs$`25-39 ans` + temp_cs$`40-54 ans` + temp_cs$distance, data=temp_cs)
summary(Hamon_CS)
tidyHamon = tidy (summary(Hamon_CS))
write.csv(tidyHamon, "Hamon.csv")
temp_cs$residusHA = resid(Hamon_CS)
# Lassalle
Lassalle_CS = lm(temp_cs$Lassalle ~ temp_cs$CS1 + temp_cs$CS4 + temp_cs$CS5 + temp_cs$CS7 + temp_cs$distance, data=temp_cs)
summary(Lassalle_CS)
tidyLassalle = tidy (summary(Lassalle_CS))
write.csv(tidyLassalle, "Lassalle.csv")
# Lepen
Lepen_CS = lm(temp_cs$Lepen ~ temp_cs$CS2 + temp_cs$CS4 + temp_cs$CS6 + temp_cs$CS7 + temp_cs$`40-54 ans` +temp_cs$`55-64 ans` + temp_cs$distance, data=temp_cs)
summary(Lepen_CS)
tidyLepen = tidy (summary(Lepen_CS))
write.csv(tidyLepen, "Lepen.csv")
temp_cs$residusLE = resid(Lepen_CS)
# Macron
Macron_CS = lm(temp_cs$Macron ~ temp_cs$CS2 + temp_cs$CS3 + temp_cs$CS4 + temp_cs$`18-24 ans` + temp_cs$`25-39 ans` + temp_cs$`40-54 ans` + temp_cs$distance, data=temp_cs)
summary(Macron_CS)
tidyMacron = tidy (summary(Macron_CS))
write.csv(tidyMacron, "Macron.csv")
temp_cs$residusMA = resid(Macron_CS)
# Melenchon
Melenchon_CS = lm(temp_cs$Melenchon ~ temp_cs$CS2 + temp_cs$CS4 +temp_cs$CS5 + temp_cs$CS7 + temp_cs$`18-24 ans` + temp_cs$`25-39 ans` +temp_cs$`40-54 ans` + temp_cs$`55-64 ans` + temp_cs$distance, data=temp_cs)
summary(Melenchon_CS)
tidyMelenchon = tidy (summary(Melenchon_CS))
write.csv(tidyMelenchon, "Melenchon.csv")
temp_cs$residusME = resid(Melenchon_CS)
# Poutou
Poutou_CS = lm(temp_cs$Poutou ~ temp_cs$CS1 + temp_cs$CS2 + temp_cs$CS4 + temp_cs$CS5 +temp_cs$CS6 + temp_cs$CS7 + temp_cs$distance, data=temp_cs)
summary(Poutou_CS)
tidypoutou = tidy (summary(Poutou_CS))
write.csv(tidypoutou, "Poutou.csv")
# Petits candidats
temp_cs$petits = (temp_cs$Poutou + temp_cs$Lassalle + temp_cs$Cheminade + temp_cs$Asselineau + temp_cs$Arthaud)
Petits = lm(temp_cs$petits ~ temp_cs$CS2+ temp_cs$CS4 +temp_cs$CS5 + temp_cs$CS7 + temp_cs$`18-24 ans` + temp_cs$distance, data=temp_cs)
summary(Petits)
tidyPetits = tidy (summary(Petits))
write.csv(tidyPetits, "Petits_reg.csv")
# Second tour
CS_age_resultats_2017_tour2_centralite <- read_csv("~/Documents/MA2/Mémoire/all_regressions/data_raw/CS_age_resultats_2017_tour2_centralite.csv",
col_types = cols(X1 = col_skip()))
tour2 = CS_age_resultats_2017_tour2_centralite
tour2 = tour2 %>%
rename( CS1 = C11_POP15P_CS1,
CS2 = C11_POP15P_CS2,
CS3 = C11_POP15P_CS3,
CS4 = C11_POP15P_CS4,
CS5 = C11_POP15P_CS5,
CS6 = C11_POP15P_CS6,
CS7 = C11_POP15P_CS7,
CS8 = C11_POP15P_CS8,
"18-24 ans" = POP1824,
"25-39 ans" = POP2539,
"40-54 ans" = POP4054,
"55-64 ans" = POP5564,
"65-79 ans" = POP6579,
"80 ans" = POP80P,
Lepen = PLEPEN ,
Macron = PMACRON
)
### second tour ###
# Lepen
tour2_temp = lm(tour2$Lepen ~ tour2$CS2 + tour2$CS5 + tour2$CS7 + tour2$CS8 + tour2$distance, data=tour2)
summary(tour2_temp)
tidyLepen = tidy(summary(tour2_temp))
round(tidyLepen,2)
write.csv(tidyLepen,"reg_2_lepen.csv")
# Macron
tour2_mac = lm(tour2$Macron ~ tour2$CS2 + tour2$CS3 + tour2$CS4 + tour2$CS7 + tour2$distance, data=tour2)
summary(tour2_mac)
tidyMacron = tidy(summary(tour2_mac))
write.csv(tidyMacron, "reg_2_macron.csv")
script ACP et carte des scores :
Je me suis basé sur ce site pour réaliser le script suivant :
# Packages needed
library(corrplot)
library(dplyr)
library(factoextra)
library(ggfortify)
library(mapview)
library(readr)
library(rgdal)
library(tidyverse)
# Inspired from here : http://www.sthda.com/french/articles/38-methodes-des-composantes-principales-dans-r-guide-pratique/79-acp-dans-r-prcomp-vs-princomp/#variables-supplementaires
CS_age_resultats_2017 <- read_csv("~/Documents/MA2/Mémoire/ACP/data_raw/CS_age_resultats_2017.csv",
col_types = cols(X1 = col_skip()))
liste_variable <- read_delim("~/Documents/MA2/Mémoire/ACP/data_raw/liste_variable.csv",
";", escape_double = FALSE, trim_ws = TRUE)
temp_cs = CS_age_resultats_2017 # Work on a temporary dataset
temp_cs = temp_cs %>%
rename( CS1 = C11_POP15P_CS1,
CS2 = C11_POP15P_CS2,
CS3 = C11_POP15P_CS3,
CS4 = C11_POP15P_CS4,
CS5 = C11_POP15P_CS5,
CS6 = C11_POP15P_CS6,
CS7 = C11_POP15P_CS7,
CS8 = C11_POP15P_CS8,
"18-24 ans" = POP1824,
"25-39 ans" = POP2539,
"40-54 ans" = POP4054,
"55-64 ans" = POP5564,
"65-79 ans" = POP6579,
"80 ans" = POP80P,
Arthaud = PARTHAUD ,
Asselineau = PASSELINEAU ,
Cheminade = PCHEMINADE ,
Dupont_Aignan = PDUPONTAIGNAN ,
Fillon = PFILLON ,
Hamon = PHAMON ,
Lassalle = PLASSALLE ,
Lepen = PLEPEN ,
Macron = PMACRON ,
Melenchon = PMELENCHON ,
Poutou = PPOUTOU
)
temp_res = temp_cs
############################# PCA on results ##############################
temp_res.pca = prcomp(temp_res[,c(22:32)], center = TRUE,scale. = TRUE)
summary(temp_res.pca)
str(temp_res.pca)
##### Get Eigen values and other #####
eig.val_res = get_eigenvalue(temp_res.pca)
fviz_eig(temp_res.pca, addlabels = TRUE, ylim = c(0,50)) # Screeplot
var_res = get_pca_var(temp_res.pca)
var_res$coord # coordinate of variables to make a cloud of the points
var_res$cos2 # cosinus ^2 of the variables ==> quality of representation of the variables on the graph
var_res$contrib # % of variables and CP
##### correlation circle and other visualization #####
head(var_res$coord, 8)
visualization = fviz_pca_var(temp_res.pca, col.var = "black", geom=c("point", "text")) +
labs(title ="Analyse en Composantes Principales", x = "CP1", y = "CP2") # visualisation of variables ==> Correct way
quanti_suppl_cs = temp_res[,3:10] # keep only columns I want to add, here CS
quanti_coord_cs = cor(quanti_suppl_cs, temp_res.pca$x) # find coordinate
fviz_add(visualization, quanti_coord_cs, color ="blue", geom=c("point","text")) # add variable quanti
temp_res.cor = cor(temp_res[,c(22:32)]) # table of correlation for the elections results
corrplot(var_res$cos2, is.corr = FALSE) # visualisation cos2 circle of the variables on all the dimensions (PC)
fviz_contrib(temp_res.pca, choice = "var", axes = 1:4, top = 5) # If I want to show only the top 5 variables contributing the most to the two first PC
autoplot(temp_res.pca) # plot all polling stations on PC1 and PC2 (fill point)
autoplot(temp_res.pca, data = temp_res.pca, shape = TRUE, label.size = 3) # plot all polling stations on PC1 and PC2
# Extract scores with an ID to map them
write.csv(temp_res.pca$x, "scoresACP_res.csv") # extract scores
temp_res <- tibble::rowid_to_column(temp_res, "ID") # Initiate same ID
scoresACP_res <- tibble::rowid_to_column(scoresACP_res, "ID") # Initiate same ID
mergedata = merge(temp_res, scoresACP_res) # join scores with bureau to map them
scoresACP_res_carto = mergedata %>% # choose only bureau and PC
select (2,35:45)
write.csv(scoresACP_res_carto, "scoresACP_res_carto.csv") # extract to csv and map them in Qgis
## Visualization
arrondissements <- readOGR(dsn = "./data_raw/arrondissements_retouches.shp", layer = "arrondissements_retouches")
arrondissements = sf::st_as_sf(arrondissements)
visuCP = scores_carto_bureau
mapview(visuACP,map.types = "CartoDB", zcol = "scoresACP_res_carto_PC1", col.regions = c("red", "grey", "snow"),
layer.name = c("PC1")) +
mapview(visuACP,map.types = "CartoDB", zcol = "scoresACP_res_carto_PC2", col.regions = c("green", "grey", "snow"),
layer.name = "PC2") +
mapview(visuACP,map.types = "CartoDB", zcol = c( "scoresACP_res_carto_PC3"), col.regions = c("blue", "grey", "snow"),
layer.name = "PC3") +
mapview(
arrondissements,
map.types = "CartoDB",
col.regions = "green",
label = arrondissements,
alpha.regions= 0,
color = "green",
legend = TRUE,
layer.name = "arrondissements",
homebutton = FALSE,
lwd = 5
)