Quels sont les liens entre le comportement électoral et la répartition spatiale des classes sociales à l’échelle intra-urbaine? En particulier, peut-on observer des différences géographiques entre les quartiers dominés par les classes intermédiaires ?
Mémoire de fin d'études présenté dans le cadre du Master en Sciences Géographiques à finalité Développement territorial

Résumé
La géographie électorale est souvent opposée à la sociologie électorale sur la base méthodologique. Seulement l’individu s’insère dans un environnement sociologique, et la simple déduction cartographique ne peut déceler l’entièreté du processus électoral.
Ce travail tente d’expliquer le vote lors des dernières élections présidentielles à Paris en 2017, et ce à l’échelle du bureau de vote. Les deux thèses principales sont le rôle de la classe sociale au sein de la décision électorale des quartiers, et plus particulièrement les différences observables au sein de ceux dominés par les classes intermédiaires.
Pour répondre à la problématique, un ensemble de données électorales et de données sociologiques a été récolté. La démarche suivie porte sur une analyse socio-géographique de la ville de Paris. A cet égard, les résultats sont croisés avec les données sociologiques agissent sur le comportement électoral, telles que la classe socio-professionnelle, l’âge et la distance au centre urbain. Cette analyse quantitative permet de catégoriser le vote des quartiers selon leur composition sociale.
Les résultats obtenus indiquent l’importance des différents facteurs sociaux au sein de la décision électorale, mais aussi qu’il ne s’agit pas de la seule explication. L’effet de voisinage semble tenir un rôle important au niveau décisionnel. La deuxième partie de la recherche portait sur les quartiers de classes intermédiaires, ceux-ci ont un vote scindé entre la droite pour les classes moyennes supérieures, et la gauche ou les extrêmes pour la classe moyenne inférieure.
Des recherches ultérieures pourraient approfondir l’effet de voisinage en se focalisant uniquement sur un quartier. Elles pourraient également s’attarder sur l’abstention, lors des dernières élections, qui semble gommer les caractéristiques sociales et devenir plus politisée. Enfin la gentrification étant fortement liée aux territoires de classes intermédiaires, une recherche de type socio-géographique combinée à de la géographie urbaine permettrait de mettre en avant les processus qui apparaissent avec la modification sociale des quartiers.
« People who talk together vote together »
Introduction
Les élections présidentielles françaises de 2017, présentent un tournant important au sein de la décision électorale, les différents clivages qui se mettent en place au sein de l’Europe depuis quelques années y sont représentés. Le président de la République, dirigeant d’une nation, est la cible d’une partie du peuple mécontent. L’exemple des luttes sociales menées par le mouvement “Gilets jaunes” indique la scission de la société française et l’importance du président dans les décisions politiques du pays. La genèse de ces luttes amène à l’analyse des élections, principalement du premier tour. Celui-ci est décisif pour le revendications sociales des citoyens français. La ville de Paris se veut être un bon cas d’étude, puisque les disparités sociales y sont fort présentes et l’organisation spatiale est très marquée socialement.
Différentes questions se posent, telles que la place des classes sociales dans la décision électorale. Est-elle majeure ou, suite à la restructuration de celles-ci, est-elle est passée au second plan ? De plus, les classes moyennes sont les plus fortement touchées pas la restructuration sociale. Sont-elles toujours une classe soudée lors des élections? Ces deux questions principales ont amené à la question de recherche : “Quels sont les liens entre le comportement électoral et la répartition spatiale des classes sociales à l’échelle intra-urbaine? En particulier, peut-on observer des différences géographiques entre les quartiers dominés par les classes intermédiaires?”.
Différents types d’analyses sont à notre disposition pour l’étude des élections, mais la combinaison d’une approche géographique avec une approche sociologique semble la plus propice. Effectivement, le vote dépend des individus et de leurs interactions. Il n’est pas possible de les extraire du contexte social dans lequel ils vivent. L’échelle intra-urbaine convient parfaitement à l’étude des phénomènes sociaux et de leurs liens avec le vote. Elle permet de catégoriser les quartiers, l’entité la plus proche des comportements réels des individus. La majorité des études sur ce sujet ont été réalisées à une plus grande échelle, observant des phénomènes qui trouvent leur origine au sein des quartiers.
Une étude à la même échelle sur les résultats des grandes villes françaises a déjà été réalisée par Rivière J. (2017), mais il s’agit d’un article introduisant brièvement l’analyse pour chaque ville. Le présent travail a pour but de déceler les dynamiques sociales du vote à Paris et les présenter de manière claires, précises et plus approfondies au lecteur.
Afin de traiter le sujet et de répondre à cette question, la recherche empirique se base sur une large littérature, essentiellement de géographie et de sociologie électorale. Le travail comporte des analyses statistiques sur des données sociologiques et électorales, ainsi que des analyses cartographiques pour visualiser spatialement la problématique.
Dans un premier temps nous établirons des recherches bibliographiques larges pour comprendre la réalisation d’une étude socio-géographique à l’échelle intra-urbaine. Ensuite nous devrons tâcher de définir les classes moyennes et catégoriser les quartiers de Paris. Nous serons également amenés à choisir une approche méthodologique pour répondre aux diverses questions posées par l’état de l’art. Par la suite, les résultats seront traités et finalement interprétés au sein d’une discussion personnelle basée sur des acquis théoriques. Enfin nous aurons une idée globale de la situation électorale à Paris.
Etat de l’art
La question de recherche est découpée afin de mieux diriger le travail. Ce sont donc les termes en gras ci-dessous qui sont les points centraux de la recherche bibliographique :
«Quels sont les liens entre le comportement électoral des quartiers et la répartition spatiale des classes sociales à l’échelle intra-urbaine? En particulier, peut-on observer des différences géographiques entre les quartiers dominés par les classes intermédiaires?»
Premièrement, nous abordons la question de l’échelle intra-urbaine. Comme il s’agit d’un élément majeur de la question, il est important de l’introduire par la littérature au sein de l’état de l’art. Par après, les différentes classes sociales sont définies, en se focalisant surtout sur les classe sociales intermédiaires comme base d’une nouvelle différenciation au sein des classes. L’impact de la gentrification est également abordé puisque celle-ci entre directement en lien avec les quartiers dominés par les classes intermédiaires. Ultérieurement, le vote est expliqué sous les différents angles possibles, à savoir l’abstention, les clivages et les différents résultats de la socialisation et de la classe.
L’échelle intra-urbaine
La plupart des ouvrages ou articles traitant de la géographie électorale ne s’intéressent pas à l’échelle intra-urbaine, à savoir l’échelle du bureau de vote. Les analyses sont dans l’ensemble à l’échelle nationale, régionale ou communale (et plus rarement départementale, selon les pays). La raison première tient du manque de données accessibles à l’échelle intra-urbaine , par exemple pour la France, les résultats présidentiels de 2017 sont seulement les seconds accessibles à l’échelle des bureaux de vote. Il est intéressant de travailler à ce niveau car ce sont les votes effectivement produits par l’électeur, ce ne sont plus des suppositions (comme le sont les enquêtes à la sortie des urnes). (Braconnier C., 2010) En analysant du niveau le plus large au niveau le plus fin, le caractère hétérogène entre les entités géographiques reste le même. Autrement dit, sachant qu’une région présente déjà des disparités avec une autre région, les bureaux de vote (ou quartiers), qui sont des entités nettement plus petites, présentent également ces différences entre eux. C’est l’hétérogénéité des résultats à petit échelle, qui influence les différences à grande échelle. (Bussi M., 2012) De plus une analyse la plus fine possible permet de mieux déceler les composantes territoriales du comportement électoral et ainsi éviter le spatialisme, autrement dit attribuer le vote à une seule composante spatiale. (Rivière J.,2012)
Les classes intermédiaires
Avant toute chose, il est important de définir une classe. Selon Chauvel L. (2006), deux éléments centraux la définisse. D’une part la position sur l’échelle économique, qui amène des conflits d’intérêt avec les autres classes, et d’autre part, la prise de conscience d’une communauté qui vise à un même destin, aux mêmes revendications. Les classes sociales jouent un rôle prépondérant au sein du comportement politique puisque la société est toujours structurée selon celles-ci. Par exemple, Gana A. (Gana et al., 2012) constate que les inégalités sociales et territoriales en Tunisie représentent une «clé de compréhension» des comportements électoraux. Les disparités sociales et territoriales croissantes durant les deux dernières décennies sont à l’origine des révoltes populaires du 14 janvier 2011.
Suite à cette définition générale, nous pouvons introduire la classe moyenne\footnote{Les termes “classe intermédiaire” et “classe moyennes” sont identiques.} et ses particularités. Différents auteurs expriment la division de la classe moyenne (Garnier J-P., 2010), et plus particulièrement son individualisation (Pinçon-Charlot, 2003), faisant écho à la seconde partie de ma question de recherche. Chauvel L. (2006) parle notamment du démembrement de la classe moyenne en lien avec la société actuelle de post-abondance (i.e. ultérieure aux trente glorieuses). Selon Van Criekingen M. et Van Hamme G. (2015), les classes sociales ont connu une restructuration complexe suite à la presque disparition du prolétariat industriel. Et surtout la perte de notion de classe est directement liée à la diminution de l’encadrement ouvrier. (David, 2011; Chauvel, 2006; Van Hamme, 2015)
L’encadrement fait ici référence aux piliers, autrement dit les structures mises en place au sein de la société qui orientent les choix électoraux, tels les syndicats ouvriers, les écoles dirigées par le parti ou encore l’église.
En conséquence de cette « disparition » de la classe ouvrière, les classes moyennes se sont également restructurées. A présent elles sont souvent exprimées en tant que classes salariées intermédiaires définies comme suit : « un groupe large et aux limites incertaines se situant entre la bourgeoisie, propriétaires de moyens de production, et le prolétariat , salariés de l’industrie et des services affectés aux tâches d’exécution » (Van Hamme G., 2012). Les limites sont floues tant au niveau supérieur qu’inférieur. Elles sont floues à la limite supérieure à cause de la grande bourgeoisie qui est à présent salariée dans les grandes entreprises, et des salariés supérieurs qui eux, possèdent souvent un capital important dans leur entreprise. Au niveau inférieur, l’autonomie et la qualification du travail auraient pu servir de définition puisque ce ne sont pas de simples emplois d’exécution. Seulement, suite à la tertiarisation accrue de l’industrie, les salariés d’exécution sont plus compliqués à définir, les tâches techniques sont de plus en plus automatisées et spécialisées tandis que les emplois classiques sont déqualifiés. (Van Hamme G., 2015)
Enfin il incombe de s’intéresser à la gentrification de Paris, pour bien appréhender le contexte de modification de la configuration socio-spatiale de Paris. La gentrification prend place principalement au Nord et à l’Est ainsi que dans les communes de la première couronne et leurs continuités. (Garnier J-P., 2010)
Selon Clerval A. (Clerval A., 2013), la gentrification est le processus par lequel l’espace urbain se modifie afin de correspondre aux rapports sociaux actuels. Elle la définit comme la dépossession des classes populaires par les « franges supérieures des nouvelles classes moyennes de la société post-industrielle ». De manière simplifiée, ces nouvelles classes moyennes pratiquant le dépeuplement des classes populaires sont des personnes qui ne peuvent pas se payer les mêmes logements que la haute bourgeoisie, mais qui appartiennent à la petite bourgeoisie intellectuelle. Elles décident d’habiter à Paris dans des logements souvent neufs ou rénovés, alors que ces logements étaient auparavant habités par les classes populaires et leur sont devenus inaccessibles.
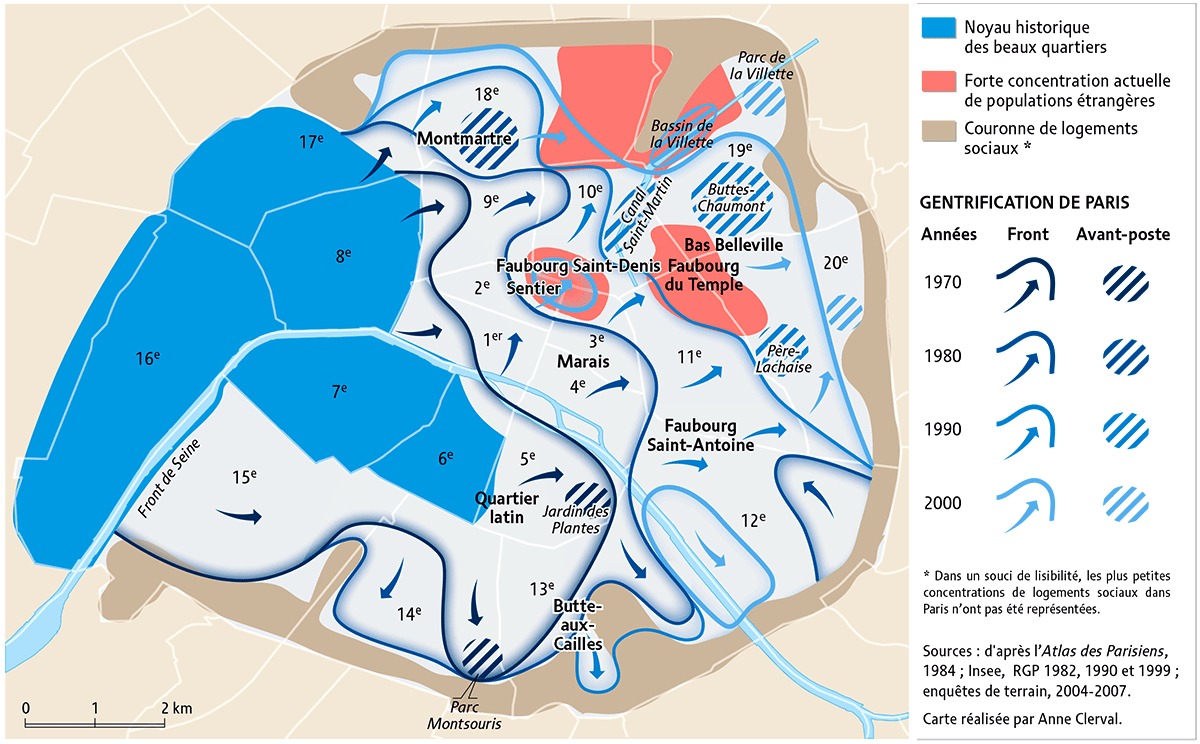
La gentrification s’installe inégalement à Paris, selon les arrondissements. Comme le montre la carte (voir Figure \ref{gentrif}), nous percevons l’accaparement des quartiers populaires par une population plus aisée. Paris connaît différentes phases de gentrification depuis les années 1960. Elles sont au nombre de quatre. La première phase se déroule entre les années 1960 et 1970, il s’agit de l’extension des beaux quartiers de l’Ouest vers les 1er, 9ème et 14ème arrondissements, ainsi qu’au sein des 5ème et 6ème arrondissements qui sont eux plus populaires. La seconde étape consiste en cette même extension mais à présent sur la rive gauche de la Seine durant les années 1980 avec les 13ème et 14ème arrondissements et une partie de la rive droite avec le 1er,2,3 et 4ème arrondissements. En 1990 un front de gentrification, se met en place en une ligne partant du 17ème arrondissements jusqu’au 12ème arrondissement. Durant les années 2000, cet axe gagne du terrain, et évolue jusqu’aux 18,19 et 20ème arrondissements, seulement il est assez faible pour les 18 et 19ème arrondissements puisque ce sont des quartiers à population étrangère importante. Un front de gentrification se base sur divers “avant-postes”. Tous les quartiers et les lieux qui permettent de s’évader de la surdensité de Paris, autrement dit les parcs, les lieux de verdure et d’eau. Sa progression n’est pas toujours continue, comme l’indique la carte. (Clerval A., 2008; Adoumie 2013)
David Ley a constaté lors de ses études sur les villes canadiennes que le vote de gauche était plus élevé dans les quartiers anciens rénovés et proches du centre ville. (Ley D., 1996) Ses découvertes ont été confirmées par d’autres auteurs, tels que Charney I. et Malkinson D. pour Tel Aviv, mais également à Paris par Adoumié V.. En effet, un quartier bourgeois comme le 16 ème arrondissement, dont la majorité de la population provient du monde de l’entreprise et où les personnes âgées de 70 ans et plus sont surreprésentés, a tendance à voter à droite. En opposition, les quartiers gentrifiés revendiquent une appartenance populaire en désaccord avec le niveau de vie de leur population et votent ainsi à gauche. C’est principalement ce qui s’observe dans les arrondissements de l’Est parisien. (Charney, 2015; Adoumie, 2013) Enfin, Van Criekingen M. et Van Hamme G. lors d’un travail sur Bruxelles se sont intéressés à la localisation des candidats (faute d’avoir des données à l’échelle du bureau de vote) et ont constaté que les candidats de gauche sont surreprésentés dans les quartiers centraux moins pauvres et/ou en voie de gentrification. (Van Hamme, 2015)
Le comportement électoral
Au niveau du comportement électoral, différents éléments sont à développer : tout d’abord l’abstention et la question de non-vote, ensuite le déclin du vote de classe avec l’arrivée massive de l’individualisme au sein des classes, l’effet de voisinage ainsi que l’ensemble des structures influençant le vote et finalement les clivages.
L’abstention, autrement dit les personnes qui ne se rendent pas aux urnes, n’a pas les mêmes causes en chaque lieu.
En France, où il n’y a pas de sanctions, l’abstention est élevée. Au niveau des inscriptions aux bureaux de vote, les personnes âgées et fortement diplômées ou possédant une situation professionnelle stable sont les plus représentées. Les citoyens nouvellement inscrits connaissent généralement une stabilisation dans le monde du travail, ou sont en construction familiale. De la même manière, les jeunes de 18-35 ans sont les plus enclins à l’abstention, ce qui peut s’expliquer par l’allongement des études et le nombre croissant de jeunes ne trouvant pas d’emploi. (Jardin A., 2014) L’autre explication survient avec la mobilité résidentielle, plus élevée chez les jeunes, et reliée directement à la non-inscription aux bureaux de vote. Selon Braconnier C., cette dernière est la raison principale de l’abstention. En effet une personne qui déménage (au sein de la France), n’est pas inscrite au bureau de son nouveau lieu de résidence et les procédures de réinscription sont longues et contraignantes. (Braconnier C., 2010 et 2014)
Jardin A. (2014) met en avant différents éléments sur l’abstention. Premièrement, même pour des élections moins mobilisantes (européennes par exemple), la participation ne diminue pas spécialement dans les classes supérieures alors qu’à l’inverse pour les classes populaires seules les élections présidentielles attirent une participation. Deuxièmement, la mobilisation nettement plus faible pour les classes populaires, et parfois décroissante, ne l’est pas de manière constante. Par exemple la mobilisation a tendance à croître lorsque la participation pour une élection moins mobilisante était très faible. Enfin il insiste sur le rôle déterminant des classes sociales sur l’abstention.
Finalement, une étude dans le cadre des élections de 2012 à Londres, a mis en lumière une relation positive entre le mode d’occupation (ménage, location) et le taux de participation. Seulement ceux-ci soulignent, sur base de la littérature, que cette relation n’est correcte que dans le cas de cette ville. (Mansley, 2015)
Maintenant que l’abstention est comprise, voyons ce qu’il en est pour le vote. La théorie adoptée depuis longtemps est celle du vote de classe.
« A person thinks, politically, as he is, socially. Social characteristics determine political preference. »
Autrement dit toute classe sociale est censée faire valoir ses intérêts et voter pour les partis les exprimant. Seulement il a déjà été démontré que les démocraties occidentales voient l’influence des classes sociales sur le vote diminuer. (Clark, 2001; De Graaf, 2000; Franklin, 1992) C’est notamment ce qui est posé dans la Sociologie de la bourgeoisie (Pinçon-Charlot, 2003) au sujet de la classe bourgeoise, elle est la dernière classe sociale mobilisée, ses membres partagent une même conscience de leur milieu social, possèdent des intérêts communs à défendre et dans ce cas-ci détiennent les ressources nécessaires pour s’exprimer dans le champ politique. Jardin A. (2014) exprime le déclin du vote de classe suite à l’affaiblissement et la désorganisation de la classe ouvrière ainsi que la diminution de l’encadrement, telles que les institutions religieuses. Il avance également que le besoin de participer dans la politique est plus faible au sein des plus jeunes générations. Selon Van Hammes G.(2012), ce déclin s’observe principalement au niveau du vote ouvrier pour qui les différents partis ne se prononcent plus ouvertement, les obligeant à se répartir sur un panel de différents partis. Seulement comme les partis de gauche ont perdu le soutien de leurs électeurs ouvriers, ils se prononcent en faveur des classes intermédiaires, ce qui provoque leur propre déclin au sein des classes les soutenant historiquement. (Van Hamme, 2012) La non-définition nette d’appartenance à une classe amène la naissance de nouveaux clivages. Cette baisse de l’encadrement joue aussi un rôle important au sein de l’abstention, comme le souligne Braconnier C. (2014). (Braconnier C., 2014)
Pour résumer, la fragmentation des classes moyennes depuis la fin des trente glorieuses amène au renouvellement tant politique que social des nouvelles classes intermédiaires. En effet elles sont tout d’abord à l’origine d’un nouveau système partisan avec la montée des partis verts, mais elles sont également fortement impliquées dans les mouvements citoyens.
Suite au déclin du vote de classe, une autre explication majeure du vote a vu le jour: l’effet de voisinage. Il a pour définition la dimension territoriale des processus politiques et sociaux. (David, 2011)
L’échelle intra-urbaine permet de déceler cet effet, en travaillant sur un quartier par exemple. Cette échelle décèle une plus grande homogénéité au sein des comportements électoraux que ne laisserait penser la composition sociale (souvent inhomogène). Il a été démontré que lorsque la classe sociale domine politiquement à l’échelle locale, elle influence le vote à l’échelle nationale. (David, 2011) Evidemment seule l’échelle intra-urbaine est intéressante pour la question, mais cela montre bien l’effet des institutions en place sur le comportement électoral.
Selon David Q. et Van Hamme G., cet effet dépend de deux facteurs. Vu qu’il est spatial, la distance a un rôle non-négligeable. Effectivement, pour qu’une personne soit influencée par le comportement social (ou électoral) d’une autre il ne faut pas que la distance soit trop élevée. Toujours dans le même ordre d’idée nous retrouvons le deuxième facteur, qui n’est autre que la densité des interactions, lorsque le nombre de contact augmente, l’effet de voisinage augmente. Les interactions prennent différentes formes: les réseaux politiques, syndicaux, militants, associatifs et informels. L’exemple le plus récurent dans la littérature est l’étude de Klatzmann J. (1957). Il a montré l’influence de l’institution majoritaire ou de la classe sociale majoritaire à l’échelle locale en travaillant sur les élections de 1956 à Paris, il en retire que 75\% des ouvriers qui vivaient dans des arrondissements ouvriers ont voté pour le parti communiste, contre seulement 55\% pour ceux qui vivaient dans des arrondissements où les bourgeois étaient majoritaires. (Gombin, 2013) Dix ans plus tard, K.R. Cox souligne également la présence non négligeable de cet effet.
Dans la littérature, l’effet de voisinage existe aussi sous la qualification d’opposition «urbain vs péri-urbain» mais il s’agit en réalité de différences entre la taille de la population, dont dépendent la quantité des interactions et la distance entre les personnes.
Le dernier aspect important au sein du comportement électorale est la théorie des clivages. Il ne s’agit pas d’un moyen d’expliquer le comportement électoral, ce sont en réalité les scissions que peuvent rencontrer des groupes aux sein d’une même entité spatiale .
Définition dans le cadre de la géographie électorale.
Certes, il existe le modèle classique de Lipset T. et Rokkan S. (1967) qui porte sur le système partisan de l’Europe de l’Ouest. Il répertorie l’ensemble des clivages rencontrés depuis le 17ème siècle, au nombre de quatre. Le premier est le clivage religieux vs laïc, qui est dû au combat politique entre l’Eglise et l’Etat. Le second est le clivage centre vs périphérie suite à l’histoire nationale de chaque pays. Le troisième est le clivage urbain vs rural, ou encore primaire vs secondaire, qui se base sur les différences socio-professionnelles. Et enfin le clivage capital vs travail datant de la révolution industrielle. (Gana, 2012)
Ces clivages, mêmes s’ils contribuent encore partiellement à la compréhension du comportement électoral, ont cédé place à de nouveaux. (Bussi M., 2002) En Europe un nouveau clivage est apparu : nouvelle gauche vs nouvelle droite (Flanagan S. 1987). Il a été observé en France en 2017 avec les résultats pour J-L. Mélenchon et M. Le Pen, mais également en Autriche où un candidat de la société civile s’opposait à un candidat d’extrême droite. Ce clivage est aussi exprimé comme une scission au sein de la société selon le niveau de diplôme.
Objectifs
La littérature sur le sujet pose une série de questions quant à ces élections présidentielles 2017.
Différents points semblent importants à relever pour fixer les objectifs du travail. Tout d’abord il s’agit de vérifier le déclin de l’influence des classes sociales sur le vote, à l’échelle intra-urbaine. Si le vote de classe présente effectivement un déclin, il faut alors s’intéresser aux autres influences que peut connaître le vote, tels que les effets de contexte, de structure (Bussi M., 2012), ou encore l’effet de voisinage. (David, 2011; Klatzmann, 1981) Dans un second temps, il convient d’inspecter la scission de la classe moyenne sur base de l’analyse électorale de ses résultats. A cette analyse s’ajoute également une confrontation avec le phénomène de la gentrification qui semble profondément modifier la structure spatiale de Paris et jouer un rôle au sein de la transformation du vote des classes intermédiaires.
Elements de contexte
Il semble important d’introduire Paris, en tant que ville globale, pour rendre compte de son importance, de ses disparités socio-économiques et ainsi justifier le choix d’étude. Par la suite nous décrirons le système électorale français ainsi que les candidats, sans qui l’élection n’est pas possible, ceux-ci sont répertoriés dans les grands mouvement du paysage électoral.
La ville de Paris
Paris est une ville de petite superficie située sur la Seine dans un bassin sédimentaire. Sa superficie est d’environ 105 km² (9 fois plus petite que Berlin par exemple), mais elle dispose d’une des densités les plus élevées au monde, elle compte 21000 hab/km² soit deux fois plus que New York.
Le système ferroviaire qui s’est mis en place à partir du 19ème siècle rayonne en partant de Paris vers la banlieue. Au fil du temps apparaît la ville de Paris telle que nous la connaissons actuellement, avec un ensemble de lignes représentant une longueur de 32 kilomètres qui longent la petite ceinture en bordure des arrondissements. Ces lignes sont accompagnées en 1973 du périphérique qui différencie Paris de sa banlieue. Paris intra-muros est la ville reprise au sein de celui-ci, le Paris des arrondissements. Il existe par ailleurs une petite couronne qui comprend la Haute Seine, la Seine Saint-Denis et le Val de Marne ainsi qu’une grande couronne qui compte le Val d’Oise, Yvelines, l’Essone et la Seine-et-Marne.
A l’échelle de la France, le grand Paris ou l’île de France ne fait que 3\% du territoire, mais compte 19\% de la population française et représente 31\% du PIB national grâce à son rôle de capitale économique. Les emplois qualifiés et la haute technologie ont remplacés les industries métallurgiques et automobiles d’antan. Depuis l’époque de la Renaissance, elle a un rôle important et à présent, Paris est reconnue comme une ville mondiale (au sens de Saskya Sassen \footnote{La ville mondiale doit être un centre de commandement dans l’économie mondiale, un site de services de grandes puissances ainsi qu’un centre financier international. Il faut qu’elle serve de lieu de développement et d’innovation dans les secteurs de la finance et des services et enfin elle doit servir de marché à ces innovations et services.}) au même titre que New-York, Londres ou encore Tokyo.
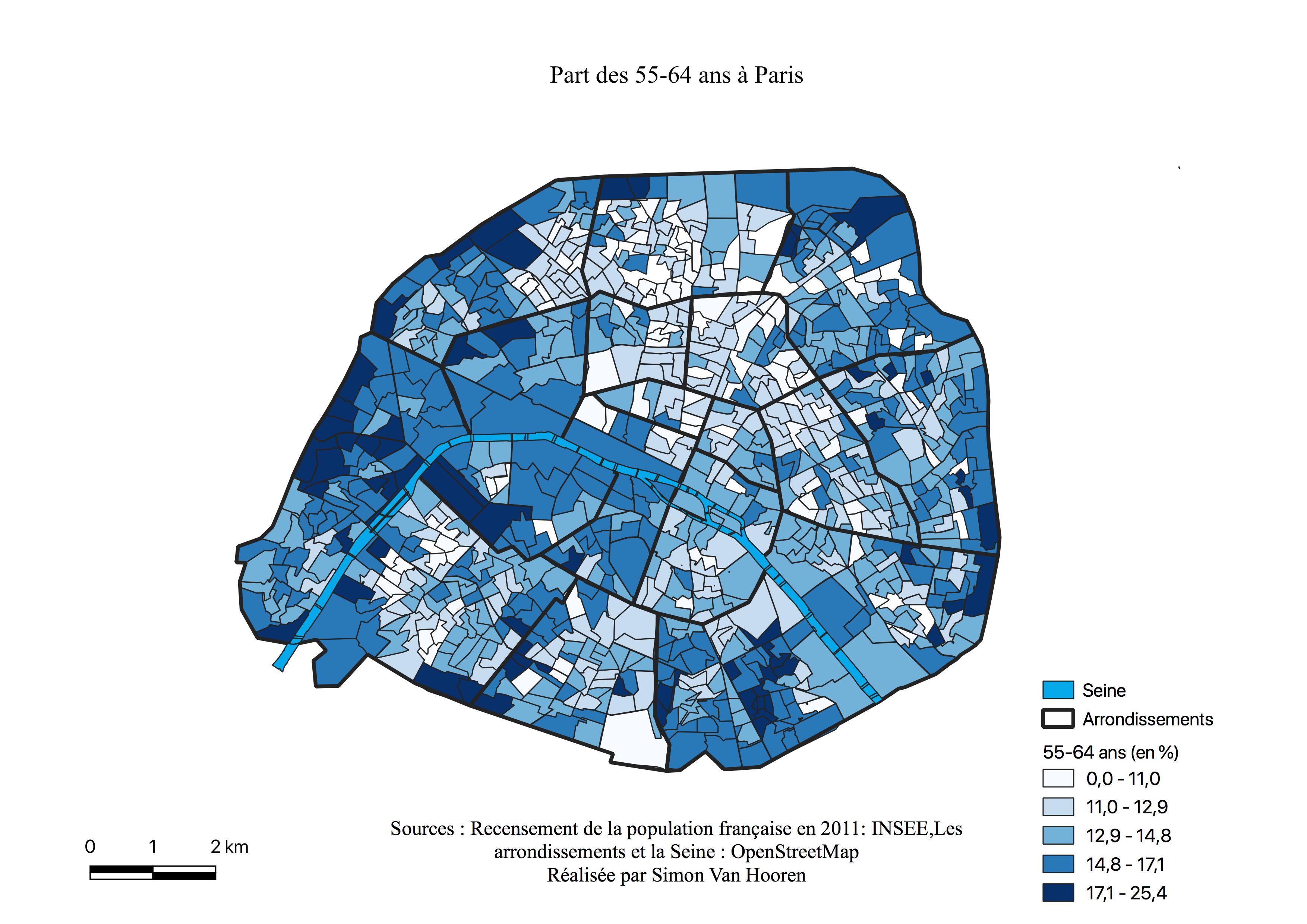
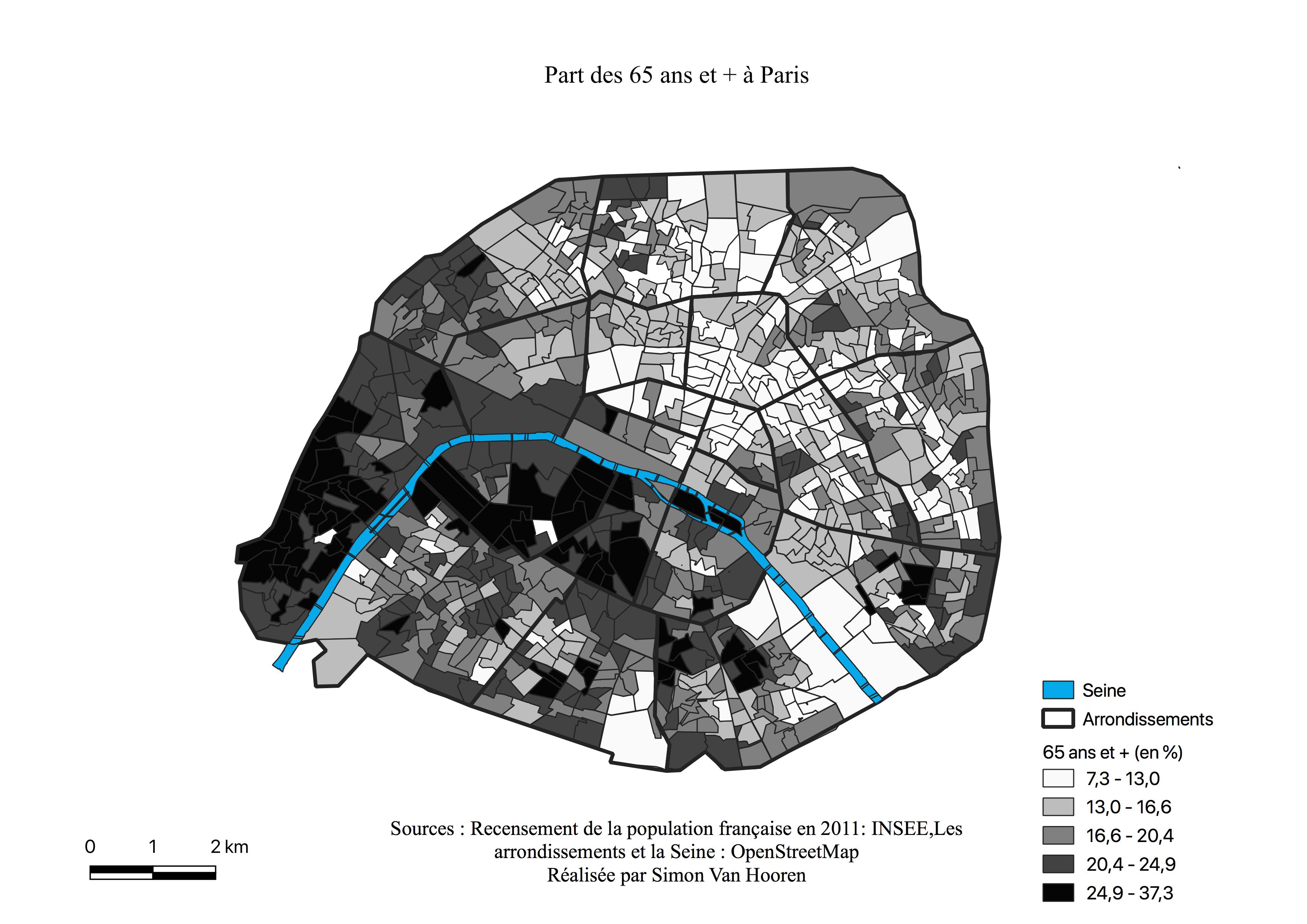
Cependant, malgré l’importance économique de la capitale, la population de Paris est assez hétérogène. Nous y retrouvons des quartiers bourgeois historiques situés à l’Ouest au sein des 6,7,8,16 et 17ème arrondissements (voir Figure \ref{arrondissements} et Figure \ref{gentrif}), des quartiers gentrifiés ( voir \ref{classmoy}) à l’Est avec les 10,11,19 et 20ème arrondissements mais également des quartiers mixtes. Certains de ceux-ci sont repris parmi les quartiers gentrifiés, d’autres sont plutôt de type populaires, il s’agit des 10,11,17,18,19 et 20ème arrondissements. Ces quartiers mixtes comportent généralement une Zone Urbaine Sensible, il en existe neuf au sein de ces six arrondissements. Elles rassemblent les habitants les plus pauvres tels que des jeunes, des sans emplois, des familles nombreuses mono-parentales ou encore des étrangers. Ces quartiers étaient périphériques, seulement suite à l’augmentation de l’importance de le ville, ils sont intégrés à Paris intra-muros. De facto des population défavorisées et des populations très aisées partagent le même arrondissement (Adoumie, 2013). La carte de la répartition des classes aisées, moyennes et populaires (voir Figure \ref{classessoc}) sur base du recensement de 2012 permet de visualiser la répartition des individus les plus riches et les plus pauvres ainsi que les classes intermédiaires.
\begin{figure}[h!] \centering \includegraphics[scale=0.7]{image/if_ina_53_Figure_2-2.jpg} \caption{Carte de la répartition des classes sociales en 2012 \citep{atelier_parisien_durbanisme_apur_les_2006}} \label{classessoc} \end{figure}
Comme le montre la répartition de la population, le statut de ville mondiale pousse à oublier la précarité, mais la population défavorisée y est fort présente suite à l’emploi sélectif. Une grande majorité des jeunes parisiens n’ont pas de diplômes et nourrissent le chômage, celui-ci est surreprésenté chez les jeunes de 18 à 25 ans, les personnes de plus de 50 ans et les non qualifiés. De plus, pour beaucoup, lorsqu’ils ont un emploi, celui-ci ne réprésente souvent qu’un mi-temps. (Adoumie, 2013) \newpage
Les élections françaises
Pour pouvoir se présenter aux présidentielles, les candidats passent par un système de parrainage qui filtre les candidats. Toute personne désireuse de se présenter doit recueillir 500 signatures de grands électeurs, ceux-ci sont des maires ou des membres des assemblées collectives Outre-mer, ils doivent appartenir à trente départements ou collectifs différent. Ces obligations assurent que les candidats représentent le niveau national et non pas uniquement départemental. En plus de ces restrictions, les grands partis organisent des élections, appelées primaires, au sein de leurs rangs pour savoir qui les représentera.
Le suffrage en tant que tel est universel et direct, à savoir que si un candidat obtient la majorité au 1er tour il est élu président. Jusqu’ici le second a toujours été nécessaire, pour celui-ci seuls les deux candidats avec les plus hauts résultats sont repris et le candidat détenant le plus haut score devient président. Les électeurs sont toutes les personnes majeures qui détiennent la nationalité française, bénéficient des droits civiles et politiques et sont rattachées à une commune. (Hamon, 2018)
Les candidats
Les élections présidentielles de 2017 présentent une conjoncture particulière. Tout d’abord les Républicains et les Socialistes qui ne parviennent pas à se mettre d’accord au sein de leurs parti respectifs et offrent chacun un candidat peu représentatif au sortir des primaires. Pour le parti socialiste, un candidat qui se place plus à gauche que le parti et qui montre certaines difficultés à se faire entendre face aux candidats de la droite. Pour les Républicains un candidat empris à des accusations personnelles. La candidate d’extrême droite qui change de discours par rapport à l’ancien Front National, berçant dans le populisme tournant son combat comme une revendication sociale et qui s’assure ainsi le second tour. Enfin le candidat d’une nouvelle faction, ni de droite, ni de gauche. Il s’agit là d’une brève typologie des grands candidats de l’élection présidentielle 2017. (Tuberj, 2017)
Bréchon P.(2017) positionne les différents candidats selon les grands clivages habituels des partis :
La gauche est représentée par Benoît Hamon (Parti Socialiste) et Jean-Luc Mélenchon (La France Insoumise). Ceux-ci mènent tous deux une politique sociale claire. Ils souhaitent revenir sur la loi travail d’El Khomri et réduire le temps de travail. Ils désirent plus de social pour les bas salaires, les précaires et les personnes sans emploi. Dans cette lignée s’ajoute une politique fiscale égalitaire. Au niveau institutionnel ils revendiquent plus de démocratie participative et souhaitent la mise en place de droits pour les étrangers. Ces candidats se veulent plus ouverts sur les moeurs tels que la légalisation du cannabis, la loi étendue pour les procréations médicalement assistées et l’euthanasie. Pour conclure les propositions similaires entre ces deux candidats, ils souhaitent tous deux la mise en place d’une politique écologique.
Leurs éléments de discorde sont l’Europe et l’ampleur des réformes institutionnelles. Jean-Luc Mélenchon se présente, sur ces questions, plus proche de l’extrême gauche que de la gauche avec le Frexit, et le retour de la démocratie au citoyen.
La droite a trois candidats pour la représenter: François Fillon (Les Républicains), Marine Le Pen (Front National) et Emmanuel Macron (La République En Marche).
François Fillon se veut le représentant des bourgeois du 16ème arrondissement, il est le nouveau candidat pour les électeurs de Sarkozy. Il défend une politique libérale et économique dans laquelle l’état intervient moins, les charges d’impôts sur les entreprises sont diminuées et la taxe sur la TVA est augmentée de 2\% tandis que celle sur les fortunes est supprimée. Ajoutons à cela qu’il désire un temps de travail passant à 39 heures et l’âge de la pension à 65 ans. De manière générale cette politique a un aspect très inégalitaire. D’un point de vue sociétal, il est pour une limitation des droits des étrangers et se veut maître d’arme d’une vision autoritaire et conservatrice, en imposant par exemple l’uniforme à l’école et l’adoption simple pour les couples homosexuels.
La candidate de la droite dure et traditionnelle Marine Le Pen, souhaite une politique sociale uniquement pour les nationaux. Cela passe par une retraite à l’âge de 60 ans et d’autres avantages pour les personnes âgées. De la même manière, la loi travail est supprimée, et une baisse de l’impôt pour les petites et moyennes entreprises, les artisans et les commerçants est prévue. Elle présente une vision protectionniste au niveau commercial, avec plus d’impôts sur l’exportation et une taxe à l’embauche de salariés étrangers. Au niveau migratoire, le solde est très réduit, le droit du sol n’est plus accepté et la sécurité sociale des étrangers est limitée. Au niveau des institutions elle propose une réduction des parlementaires, des référendum réguliers. Enfin une politique sécuritaire est mise en place, la perpétuité est non négociable, les homosexualité perdent le droit au mariage et les procréations médicalement assistées reviennent uniquement aux couples stériles.
Enfin, Emmanuel Macron, est le candidat le plus compliqué à situer, mais sa politique libérale pour les entreprises l’amène à être rattaché à la droite. Il souhaite une baisse des charges patronales et la suppression des cotisations salariales, pour compenser il souhaite augmenter les contributions salariales généralisées. Enfin, pour lui l’impôt sur la fortune a bien lieu, mais uniquement sur l’immobilier. (Brechon, 2017)
Le reste des candidats présents lors de ces élections, font partie des petits candidats selon la loi du 15 janvier 1990 La loi du 15 janvier 1990 définit un seuil de scores (5\%) en dessous duquel un candidat est un petit candidat.}. Cette définition sert à la différenciation des niveau de plafonnement du remboursement des frais de campagnes entre les candidats. (Erhard, 2017)
Ceux-ci sont également classables en fonction de leur programme (Le monde, 2017) :
- Nathalie Arthaud et Philippe Poutou sont les représentants de l’extrême gauche communiste.
- Nicolas Dupont-Aignan et François Asselineau ont une vision proche de l’extrême droite, même si ils souhaitent en être différenciés tous les deux. Ils sont pour un Frexit et la remise en question de l’Europe.
- Jacques Cheminade est montré comme un eurosceptique et conspirationniste, et son programme ne permet pas de réellement le situer.
- Jean Lassalle représente la droite rurale d’antan.
Méthodologie
Choix de l’approche méthodologique
Au sein de la bibliographie, il existe deux méthodes qui sont longtemps restées opposées sur les fondements de l’analyse électorale. Ces deux méthodes sont l’analyse sociologique et l’analyse écologique. La première se base sur les données sociologiques généralement attribuées aux recherches de sociologie électorale, elles s’appuient sur des sondages d’intention de vote ou d’opinion. Elles comportent le risque majeur de ne pas tenir compte de l’origine sociale déjà dénoncé en 1973 par P. Bourdieu.
La seconde méthode utilise les données écologiques attribuées aux géographes électoraux. Elles consistent en une carte réalisée sur base des résultats électoraux agrégés à différents niveaux géographiques et permettent d’en tirer des conclusions. Le risque majeur étant ici l’erreur écologique, autrement dit déduire des comportements individuels à partir de moyennes collectives. (Gombin, 2014)
Il a été démontré que l’on ne peut sortir l’individu de son contexte social. La structure des catégories socio-professionnelles n’a pas les mêmes influences sur le vote en fonction du lieu, montrant que les classes sociales votent inégalement en fonction de leur territoire et du contexte social. Le contexte apparaît plus important en travaillant non plus à l’échelle nationale mais à une échelle plus fine (région, départements, quartiers). (Bussi M., 2012; David, 2011; Van Hamme, 2012; Gombin, 2014)
Suite à l’ensemble de ces connaissances ainsi qu’à l’existence de données à plus petite échelle, nous pouvons mettre en relation l’appartenance à la classe sociale et la position spatiale. A présent les analyses ne sont plus strictement géographiques ou strictement sociologiques, la plupart sont des analyses socio-géographiques. Un article de Gombin J. et Rivière J. répond à la question (par la négative) de la légitimité actuelle de distinguer géographie et sociologie électorales. (Gombin J., 2014) Celles-ci permettent d’enquêter sur la dimension spatiale du social et limitent ainsi les erreurs de l’une comme de l’autre. Bussi M. (2012) de rajouter qu’en croisant les données des recensements avec les résultats des élections, nous pouvons observer le poids et la structure de chacune des catégories socio-professionnelles et ainsi voir les disparités entre les quartiers. (Girault, 2001; Rivière J, 2012; Van Hamme, 2012; Bussi M., 2012)
Obtention et traitement des données
Au travers de ce mémoire différentes données sont exploitées, celles-ci sont toutes d’origine OpenSource, i.e. elles sont disponibles en libre accès sur internet. Il convient de travailler avec les données les plus précises mais également les plus récentes disponibles.
Pour les données électorales, nous travaillons sur les résultats des élections présidentielles 2017 à l’échelle du bureau de vote. En 1979, A. Lancelot exprime la partinence de l’échelle des bureaux de vote: “En se plaçant au niveau d’agrégation le plus fin, […] le chercheur construira ses hypothèses à partir de données électorales d’une grande solidité, qui présentent la particularité devenue une rareté aujourd’hui, de correspondre à l’enregistrement de pratiques politiques effectives.” En effet, les variations régionales du vote, ne sont généralement que le résultat de l’ensemble de variations au niveau infra. (Braconnier C., 2010) Ces données proviennent de DataGouv , l’office de partage des données du gouvernement de Paris et elles ont été remodelées par Arthur Cheysson, disponibles sur son site. Les résultats reprennent les départements, les bureaux de vote de 2017, le nombre de vote total, le nombre d’inscrits, les nombre d’exprimés, et les résultats (en nombre de vote) pour chaque candidat des élections présidentielles 2017 ainsi que de nombreuses informations complémentaires que nous n’utilisons pas dans ce travail. Les résultats portent sur l’ensemble de la France (hors Mayotte).
Les données sociologiques les plus récentes datent de 2011, il s’agit du recensement de population français de l’INSEE. Ces données reprennent le code IRIS (Ilôts Regroupés pour l’information statistique et d’autres codes d’identification géographiques, différents chiffes, tels que le nombre de la population à un certain âge pour un certain sexe ou pour les deux sexes, le nombre de personnes appartenant à une certaine catégorie socio-professionnelle ainsi que des informations comme l’origine et le type de ménage.
Les secteurs des bureaux de vote de 2012 et 2017 à Paris sont exploités sous format GeoJSON. Les deux proviennent d’OpenData. Dans les deux cas ils reprennent les polygônes géographiques des bureaux de vote et le nombre d’électeurs inscrits par bureaux. Les bureaux de vote de 2012 sont au nombre de 867 tandis que ceux de 2017 sont au nombre de 896. Les secteurs IRIS sont également utilisés, ils proviennent de DataGouv
Pour la cartographie, les arrondissements de Paris, la Seine et Notre Dame sont des shapefiles extraits d’OpenStreetMap. Ils sont surimposés aux secteurs des bureaux de vote de 2017.
L’ensemble de ces données sert de base pour des démarches statistiques et cartographiques mais ces données doivent être préalablement traitées et différentes étapes sont nécessaires. Tout d’abord la ventilation des données sociologiques de l’INSEE, ensuite la création d’un identifiant commun entre les secteurs des bureaux de votes de 2012 et ceux de 2017. Grâce à cela, le croisement des données sociologiques et des résultats électoraux est possible. Ensuite,afin de faciliter l’analyse et d’offrir une visualisation précise du contexte, un ensemble de cartes électorales et sociales est produit. Enfin, pour offrir une analyse scientifique précise, des traitements statistiques sont effectués sur les différentes données sociologiques et électorales.
Ventilation des données
Les données sociologiques de 2011 et les résultats électoraux de 2017 nécessitent d’être mis à la même échelle pour pouvoir les analyser. Afin d’obtenir des données exploitables à l’échelle des bureaux de vote de l’élection présidentielle 2017, une démarche statistique est nécessaire.
Premièrement un dénominateur identique entre la tables des données INSEE et celle des résultats de l’élection 2017 est nécessaire. Un problème apparaît lors de la mise en commun des données sociologiques INSEE et des bureaux de vote de 2012, elles sont pas joignable mis à part via la géométrie. La table des données sociologique INSEE contient un identifiant IRIS partagé avec les secteurs IRIS. Les données IRIS doivent être redistribuées au sein des polygones des bureaux de vote de 2012.
Pour la ventilation des données d’une échelle à une autre de l’échelle IRIS à l’échelle des bureaux de vote de 2012. nous avons utilisé le package “Reapportion data from one geography to another in R” de Joël Gombin L’entièreté de ce script est disponible sur le Github de Joël Gombin . Celui-ci prend en entrée les données sociologiques de 2011, les géométries IRIS et celles des bureaux de 2012. Ce package propose de ventiler les données en partant du principe que les données ont une répartition homogène au sein des polygones. Cette ventilation effectuée, les données sociologiques ont à présent un identifiant qui les relie aux bureaux de votes de 2012.
Le résultat de la ventilation ne permet toutefois pas la mise en commun des données IRIS (à présent à l’échelle des bureaux de vote de 2012) et les résultats des élections (à l’échelle des bureaux de vote de 2017). Après de nombreuses recherches, il apparaît que la création d’un identifiant commun n’est pas automatisable. En effet, un ensemble de bureaux de vote sont disposés différemment selon qu’ils appartiennent à l’année 2012 ou à l’année 2017, rendant impossible la superposition des données par la géométrie. Il faut se résoudre à rajouter manuellement l’identifiant IRIS des bureaux de 2012 dans la table des bureaux de 2017.
Il aurait été plus judicieux de directement appliquer la ventilation au sein des bureaux de 2017, mais les données récoltées pour les bureaux de vote de 2017 ne contiennent pas l’identifiant IRIS, nécessaire à l’utilisation du package SpReapportion.
Nous détenons un lien entre les deux tables donnant la table finale. Celle-ci contient :
- les données sociologiques de 2011
- les résultats électoraux de 2017
- la géométrie des polygones des bureaux de vote de 2012 et 2017.
Elle est ensuite traitée de manière à ne conserver que les données sociologiques nécessaires (la population totale, l’âge, les catégories socio-professionnelles), les résultats électoraux (le nombre d’inscrits par bureau, les résultats en nombre de votes de chaque candidats par bureau) et l’identifiant des bureaux de vote de 2017. L’ensemble de ces données sont transformées en pourcentage. Lors de la ventilation, et plus exactement de l’insertion des identifiants des bureaux de vote de 2012 au sein de ceux de 2017, certains choix sont réalisés, notamment lorsque deux ou plusieurs bureaux de 2017 se retrouvent sous un seul bureau de 2012, l’identifiant de 2012 est insérée dans chacun des bureaux de 2017. A l’inverse, lorsqu’il existe plusieurs bureaux de 2012 qui se superposent pour un de 2017, la somme des deux est introduite. Quand un ensemble de bureaux se chevauchaient et partageaient un bureau de 2017 en deux, celui avec le plus grand nombre de population a été utilisé. Enfin 26 bureaux de vote de 2017 n’ont pas trouvé de correspondants en 2012. De même, les résultats des régressions et de l’Analyse en Composantes Principales sont basés sur 860 bureaux et non pas 896.
L’ensemble du traitement statistique est réalisée à l’aide du logiciel RStudio. Tous les codes produits seront disponibles sur ma page Github.
La cartographie
Mis à part les traitements des tables de données\footnote{Ces traitements sont réalisés au sein de RStudio, l’ensemble des cartes sont réalisées dans le logiciel de SIG OpenSource QGIS. La cartographie permet d’observer rapidement l’information, mais surtout de visualiser et contextualiser ce qui est exprimé. Dans un premier temps, une carte des arrondissements de Paris est produite pour aider le lecteur à les situer ainsi que différentes carte des classes sociales par bureaux de votes. Ensuite, un ensemble de cartes électorales est réalisé, tel que l’abstention au 1er et second tour, les résultats du 1er tour pour l’ensemble des grandes candidats, au nombre de cinq, une carte reprenant les résultats sommés des petits candidats et une carte des résultats de chacun des deux candidats lors du second tour.
Convention
Pour que les cartes puissent être comparées, elles nécessitent la même convention, à savoir qu’elles comportent toutes un shapefile des bureaux de vote de Paris intra-muros en 2017, un shapefile des arrondissements pour mieux se situer, et un shapefile modifié des cours d’eau à Paris pour ne garder que la Seine. Par ailleurs, chaque carte est projetée selon le même EPSG : Lambert zone II, 27572 centré sur Paris ainsi que la même échelle 1:50000.
La centralité
Pour calculer la distance au centre (voir \ref{regmultiple}) de chaque bureau, la cathédrale de Notre Dame de Paris est utilisée comme point central de Paris. Sa localisation est récupérée, introduite dans un fichier CSV contenant “Name/lon/lat”. Celui-ci sert à la création d’un point (EPSG27572) sur la carte. Ensuite les polygones des bureaux de votes sont convertis en points via le plugin MMQGIS où nous spécifions que le package doit se baser sur les centroïdes des polygones. Au final nous calculons la distance entre les différents points via la matrice des distances de l’outil d’analyse de QGIS. Cette nouvelle colonne est extraite et ajoutée à la table contenant les résultats de votes, les catégories socio-professionnelles et l’âge.
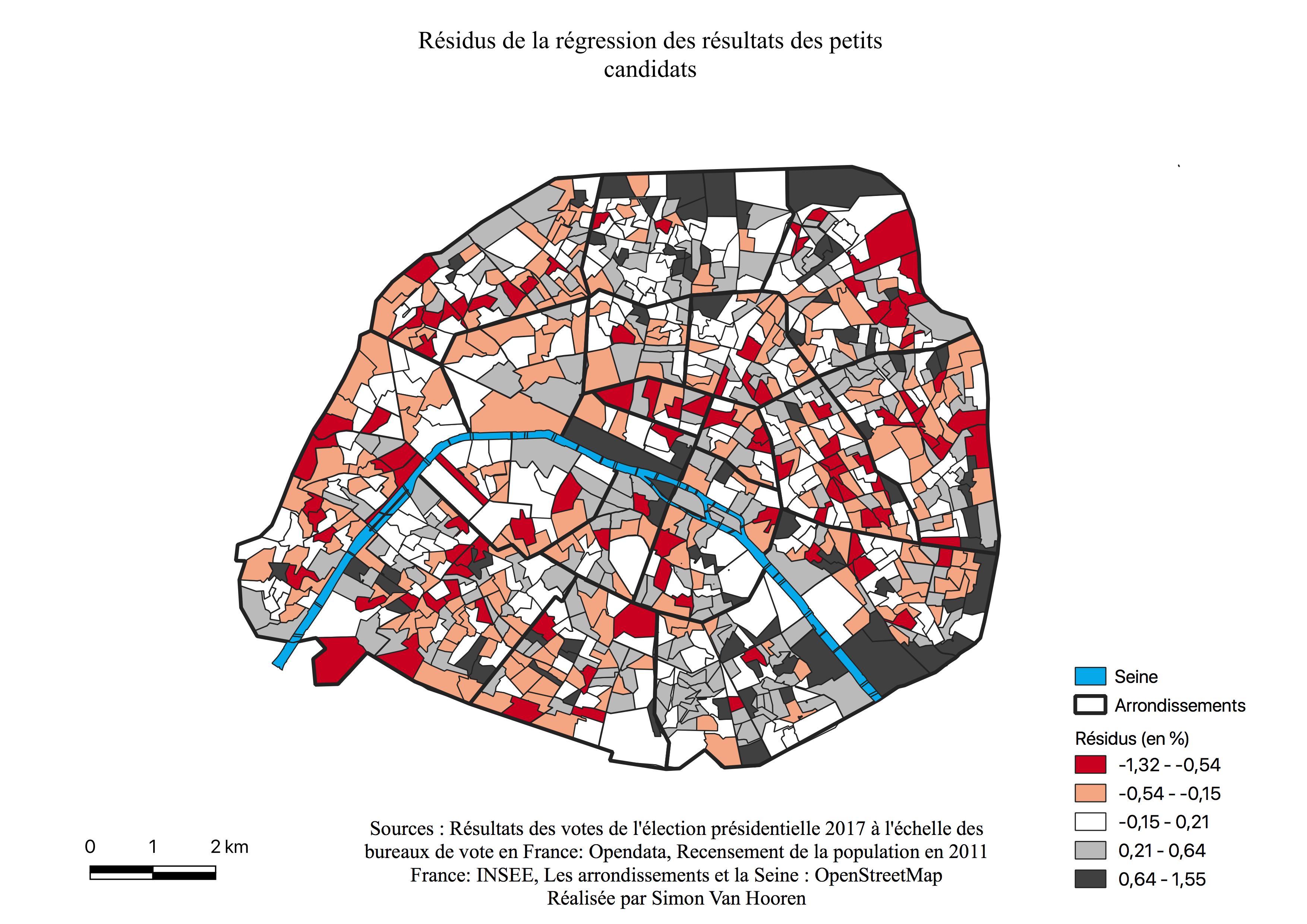
Les petits candidats
Sur base de la somme de l’ensemble des résultats des cinq grands candidats, les abstentions, les non-votants, on obtient près de 95\% des votes. Une carte des petits candidats est intéressante si une géographie est observable. Afin de cartographier les résultats des votes pour l’ensemble des petits candidats, il faut sommer leurs résultats puis cartographier le résultat.
Les cartes électorales
La démarche est la même pour l’ensemble des cartes. Les données utilisées sont les pourcentages de vote des inscrits. En effet, le calcul des pourcentages de vote sur base du nombre d’électeurs inscrits au moment des élections par bureau de vote, rend compte du poids de l’abstention, contrairement aux pourcentages sur base des suffrages exprimés. (Rivière J., 2013)
\begin{table}[h] \footnotesize \begin{tabular}{|l|l|l|} \hline Carte & Distribution & Mode de discrétisation possible \ \hline Fillon & assymétrique à gauche & Ecart type / Ruptures naturelles (Jenks)/ Quantiles égaux \ \hline Hamon & symétrique & Ecart type / Ruptures naturelles (Jenks)/ Quantiles égaux \ \hline Le Pen & assymétrique à gauche & Géométrique / Rupture naturelle (Jenks) / Quantiles égaux \ \hline Macron & symétrique & Ecart type / Ruptures naturelles (Jenks)/ Quantiles égaux \ \hline Mélenchon & multimodale & Ruptures naturelles (Jenks)/ Quantiles égaux \ \hline Petits candidats & symétrique & Ecart type / Ruptures naturelles (Jenks)/ Quantiles égaux \ \hline Le Pen 2ème tour & assymétrique à gauche & Ecart type / Ruptures naturelles (Jenks)/ Quantiles égaux \ \hline Macron 2 ème tour & assymétrique à droite & Ruptures naturelles (Jenks)/ Quantiles égaux \ \hline \end{tabular} \caption{Ensemble des histogrammes et modes de discrétisation.} \label{tab:discretisation} \end{table}
Pour la discrétisation de l’ensemble des cartes électorales les histogrammes sont analysés (voir Table \ref{tab:discretisation}), les ruptures naturelles de Jenks conviennent dans chacun des cas. Le choix de 6 classes est effectué pour chaque carte afin d’observer au mieux les différences à l’échelle intra-urbaine.
Traitements statistiques
La démarche statistique prend une place importante au sein de la géographie électorale dans la mesure où simplement tirer des résultats sur base de cartes ne suffit pas et représente une erreur écologique. Il faut se baser sur des résultats empiriques pour pouvoir extraire les réels liens entre le vote et les quartiers (Rivière J, 2013) Le premier traitement réalisé est celui de l’Analyse en Composantes Principales, qui sert à réduire l’information sur de nouveaux de systèmes d’axes pour tenter d’extraire une logique au sein du vote. Le second traitement n’est autre que la régression linéaire qui vérifie les relations entre une variable et un ensemble de variables explicatives.
L’Analyse en Composantes Principales (ACP)
L’analyse en composantes principales est une analyse factorielle permettant de travailler avec de grands nombres de variables pour de grands nombres de lieux. Les colonnes sont regroupées en un nombre plus restreint de facteurs. Plus les variables sont corrélées, moins il y a de facteurs, appelés les composantes principales. Celles-ci sont un nouveau système d’axes qui représente au mieux le nuage de points des observations. Chaque composante principale détient la plus grande partie possible de la variance totale offrant une information statistique réduite.
Les composantes principales ont la particularité d’être orthogonales les unes aux autres, le 1er axe reprend le maximum possible de la variance, le second perpendiculaire va en diminuant et ainsi de suite.
Les axes se rejoignent en un point: le centre de gravité. Il s’agit de la valeur moyenne de chaque variable. De plus les composantes principales sont parfaitement non corrélées entre elles, chacune donne une part non redondante de l’information. (Rivière J., 2017)
Dans le cadre de ce travail, l’Analyse en Composantes Principales est appliquée sur l’ensemble des candidats du premier tour, afin de déceler les clivages ayant pris place durant les élections présidentielles 2017. Dans une optique socio-géographique, les classes sociales sont ajoutées en variables complémentaires après les avoircentrées-réduites pour être dans le même système d’axe. L’ensemble du traitement est réalisé à l’aide du programme statistique R.
Les régressions linéaires multiples
La régression linéaire multiple (ou multivariée) permet d’analyser des relations entre une variable dépendante et une multitude de variables explicatives. Les variables sont généralement corrélées un minimum entre elles, c’est pourquoi il arrive souvent de revenir par après sur ses analyses de régression multiples pour supprimer l’une ou l’autre variables indépendantes.
Dans le cadre de ce travail, le choix des variables indépendantes est fait de manière intuitive dans un premier temps. Celles-ci sont les classes socio-professionnelles de l’INSEE, les catégories d’âge (à partir de 18ans, la majorité de vote) et enfin la distance à Notre Dame qui servira d’indice de centralité. Les variables de l’INSEE permettent de situer l’électorat de manière sociale et d’observer si des effets de structures sont en jeu. La distance au centre sert à mettre en avant différents processus, par exemple la relégation des classes moyennes inférieures en bordure de la ville suite à l’augmentation des loyers dans le centre. Cette variable est fortement liée à la spatialité des variables sociologiques lourdes. (Bussi M., 2012; Jardin A., 2014) En introduisant ces variables socio-professionnelles dans la régression multiple, il est possible de déceler les corrélations qui existent avec la répartition territoriale des résultats.
La choix de l’information qui est introduite dans chaque régression multiple est fait en amont. Pour ce faire, les variables indépendantes les mieux corrélées à la variable dépendante sont introduites. Celles-ci sont définies sur base d’un test de corrélation, il s’agit d’un tableau reprenant l’ensemble des variables dépendantes et indépendantes ainsi que leur degré de corrélation les unes envers les autres. Si les variables introduites sont multicolinéaires (Voir Annexe \ref{tab:table_cor}), autrement dit si le R2 est supérieur à 0.5, il faut choisir d’introduire l’une ou l’autre en fonction de la plus corrélée avec la variable à expliquer. La méthode développée ici est dite de “stepwise regression”, autrement dit après chaque régression avec les variables décidées en amont, une modification des variables est effectuée jusqu’à ce qu’une suppression ou un ajout de variable entraîne une diminution du R2 ajusté. (James, 2013; Van Criekingen, 2018) Une nouvelle fois, l’analyse de régression linéaire multiple est réalisée au sein du programme statistique R.
Résultats
Dans ce chapitre sont présentés l’ensemble des résultats, nous y retrouvons les cartes utiles à la visualisation du phénomène électorale étudié, les résultats statistiques, à savoir l’analyse en composantes principales qui permet de synthétiser l’information (voir \ref{explacp}) ainsi que les résultats des régressions linéaires multiples (voir \ref{regmultiple}).
La cartographie
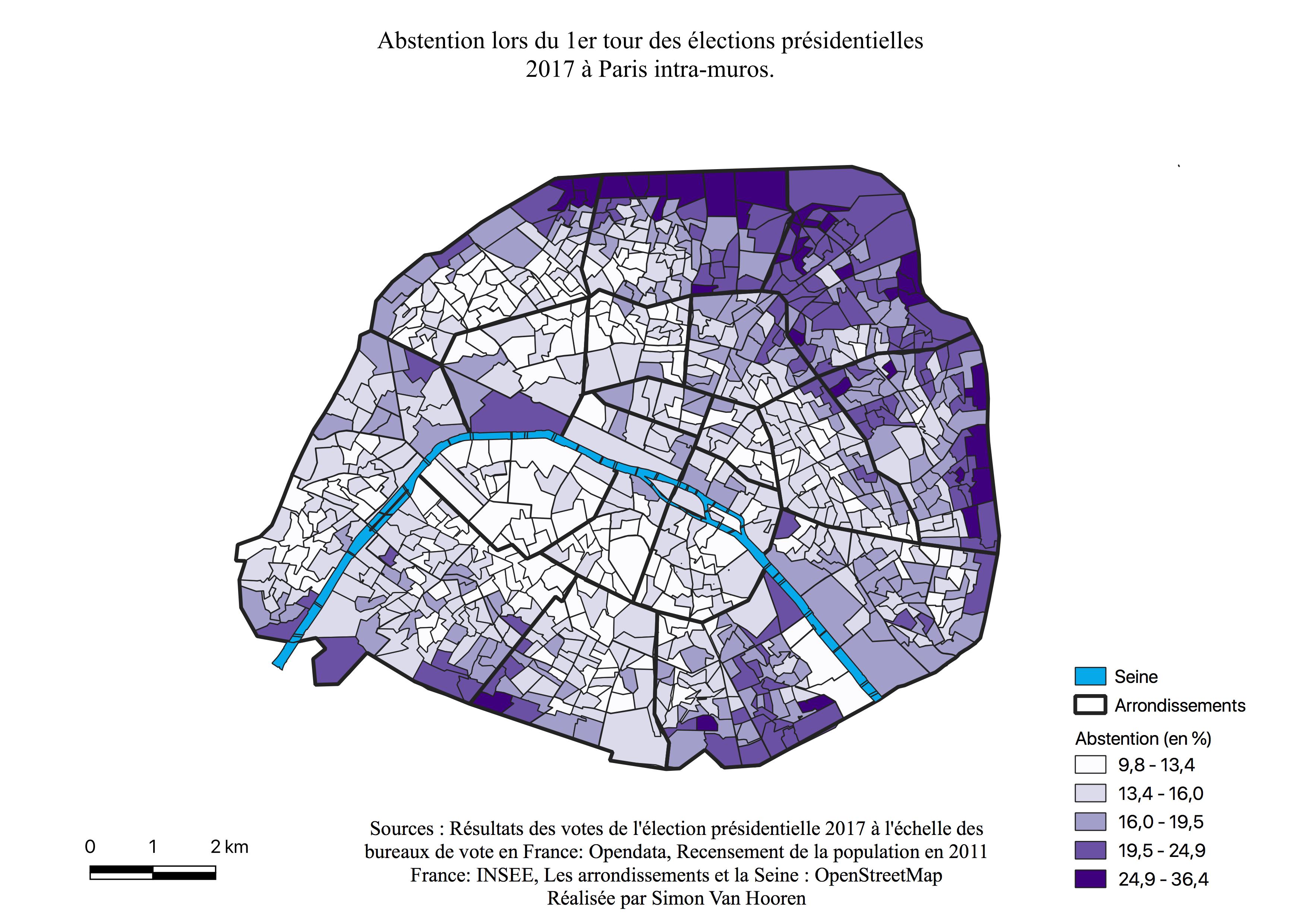
L’abstention lors du premier tour
La géographie de l’abstention lors de ce premier tour connaît un léger gradient Est-Ouest. La périphérie représente les scores les plus élevés, entre 20 et 36 %. Nous retrouvons également une zone plus faible à l’intérieur du 16ème (entre 10 et 16%), zone des beaux quartiers historiquement (voir Figure \ref{classessoc}). L’abstention est uniquement cartographiée au sein de ce travail pour aider à visualiser le contexte, mais chercher à la comprendre et à l’expliquer relève d’un travail à part entière.
L’électorat de François Fillon
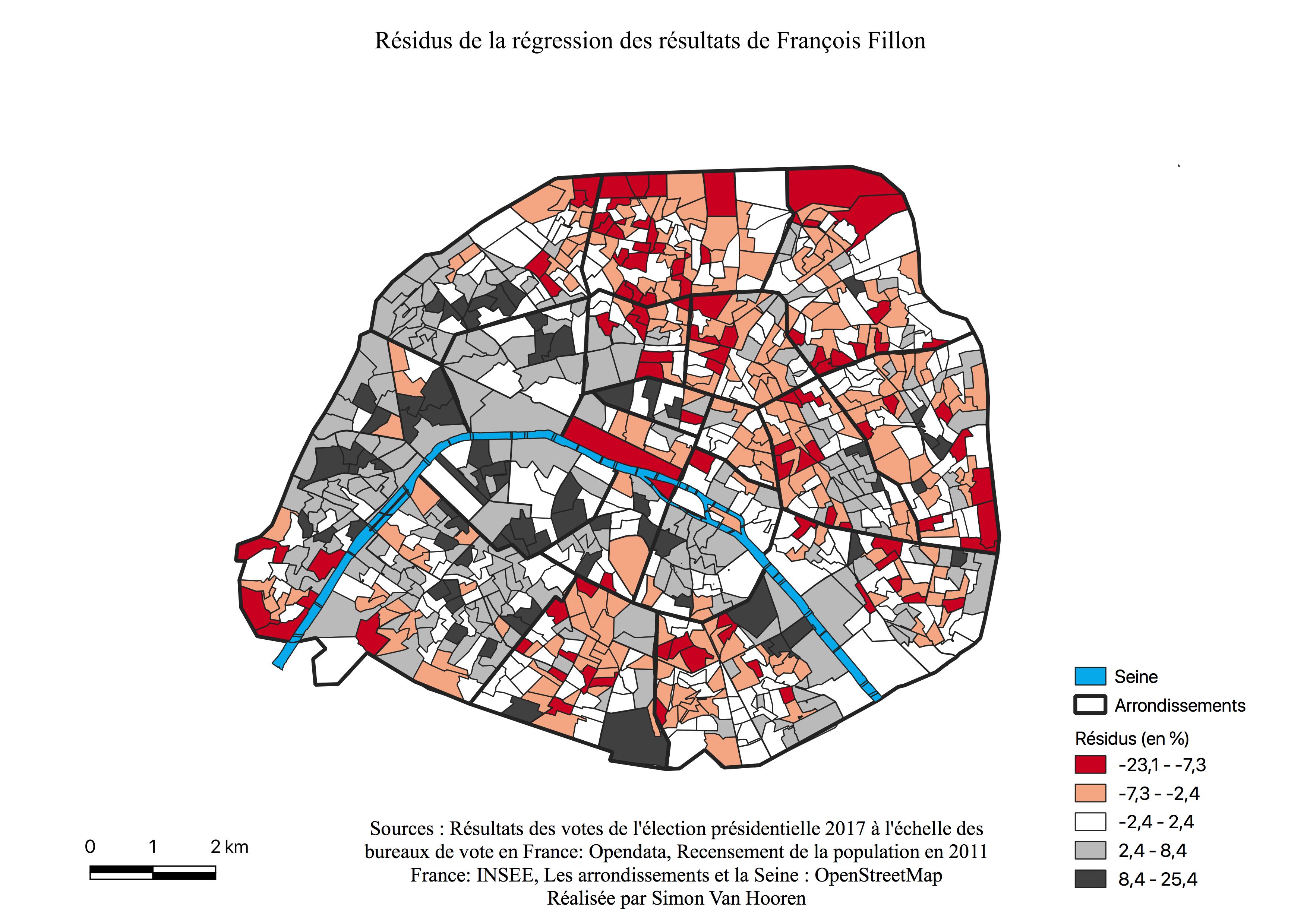
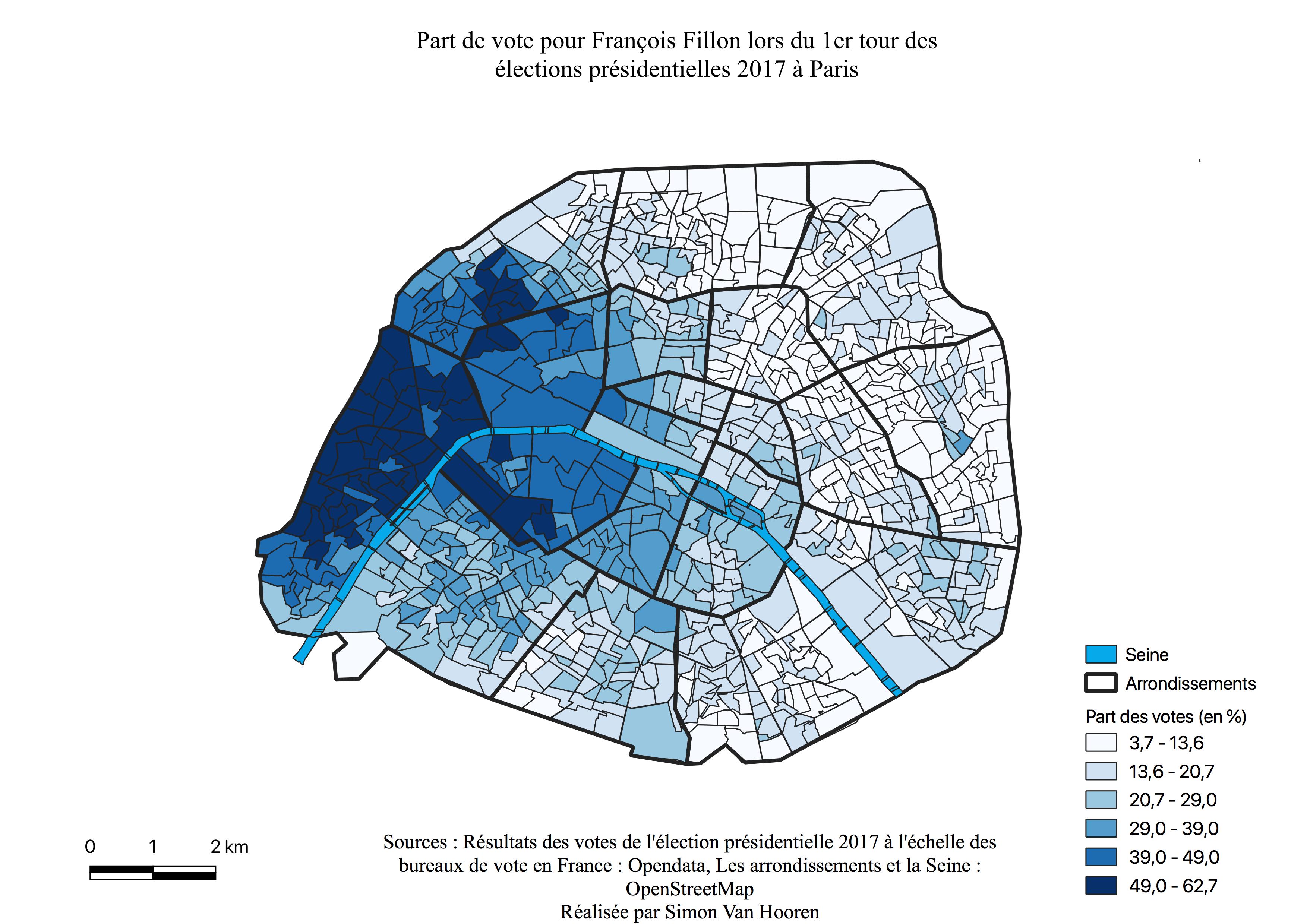
L’histogramme de François Fillon (voir Annexe \ref{H1F}), est assymétrique à gauche, la majorité des valeurs se situent entre 10 et 20%, mais il connaît malgré tout un bon nombre de quartiers ayant voté pour lui à de meilleurs scores. François Fillon est l’un des candidat principaux à Paris.
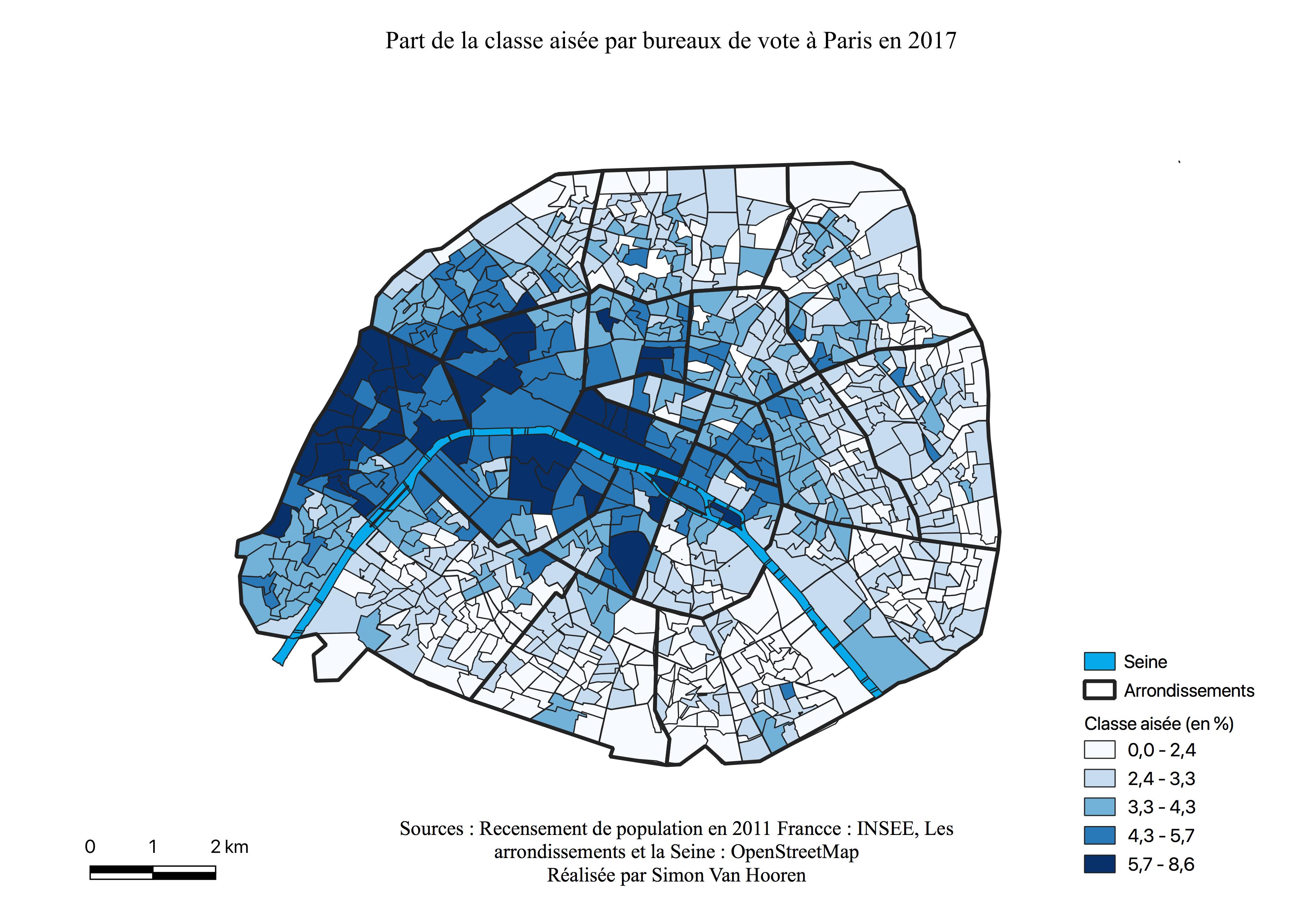
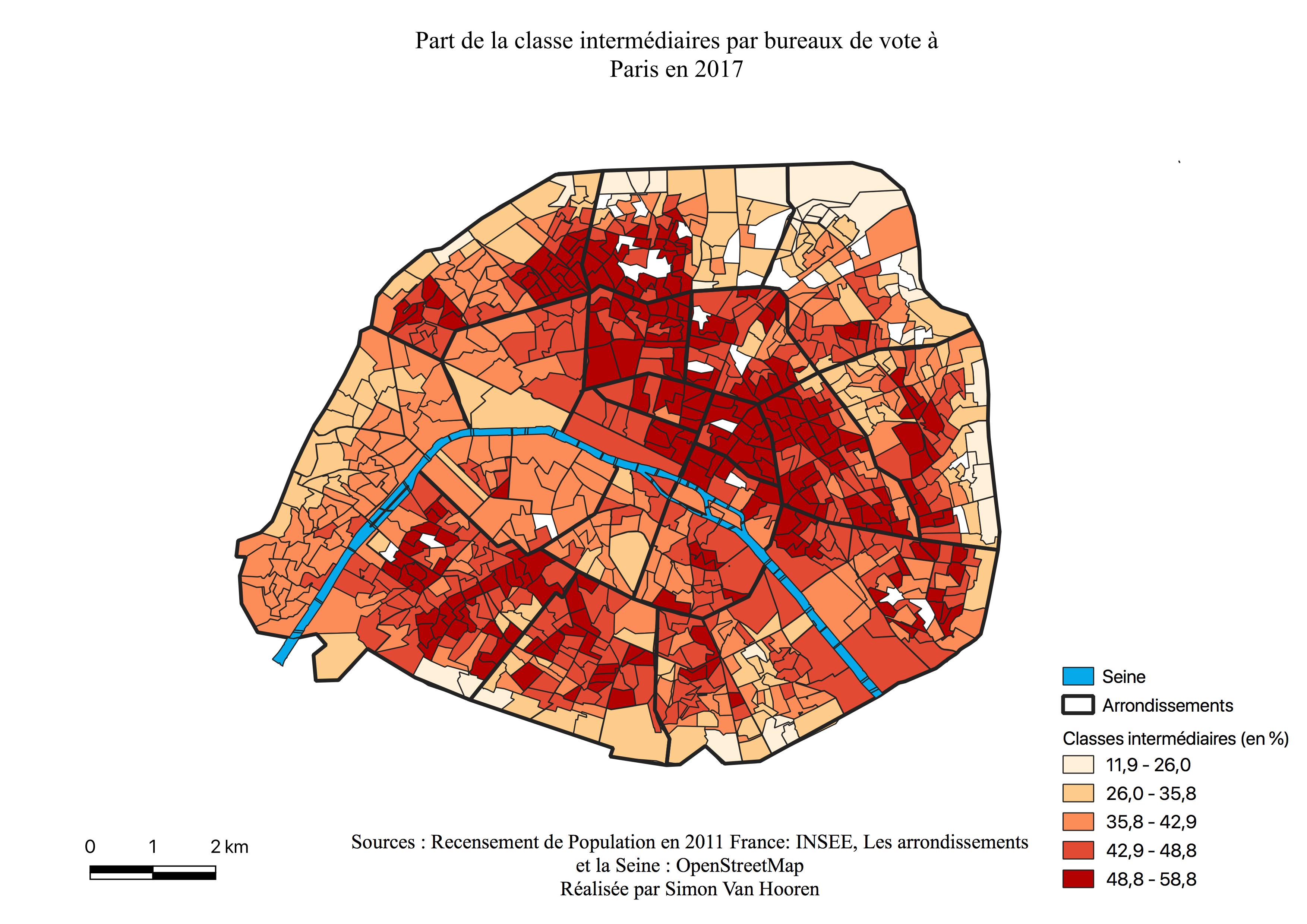
Les bureaux de vote ayant le plus voté pour François Fillon sont concentrés à l’Ouest (voir Figure \ref{C1F}), au sein des 7ème, 8ème, 16 ème et 17 ème arrondissements, mais également des 1er, 2ème, 9ème et 15ème arrondissements avec des scores moins élevés. Nous pouvons observer une similitude entre la carte de l’électorat de François Fillon et la carte des classes aisées à Paris (voir Annexe \ref{aises}) La majorité des quartiers des arrondissements de l’Est ont des résultats plus faibles. Comme le présageait, l’histogramme la majeure partie des bureaux ont voté faiblement pour ce candidat quoique ces scores évoluent malgré tout jusqu’à 20%. La Seine constitue une frontière pour l’électorat de François Fillon. Enfin, l’ensemble des quartiers qui représentent ses plus faibles pourcentages de vote, sont repris en un croissant à l’Est, ceux-ci semblent être les zones de survote pour de Jean-Luc Mélenchon (voir Figure \ref{C1M}) et Benoît Hamon (voir Figure \ref{C1H}), mais également de surreprésentation des classes moyennes et populaires (voir Annexes \ref{interm},\ref{popu}).
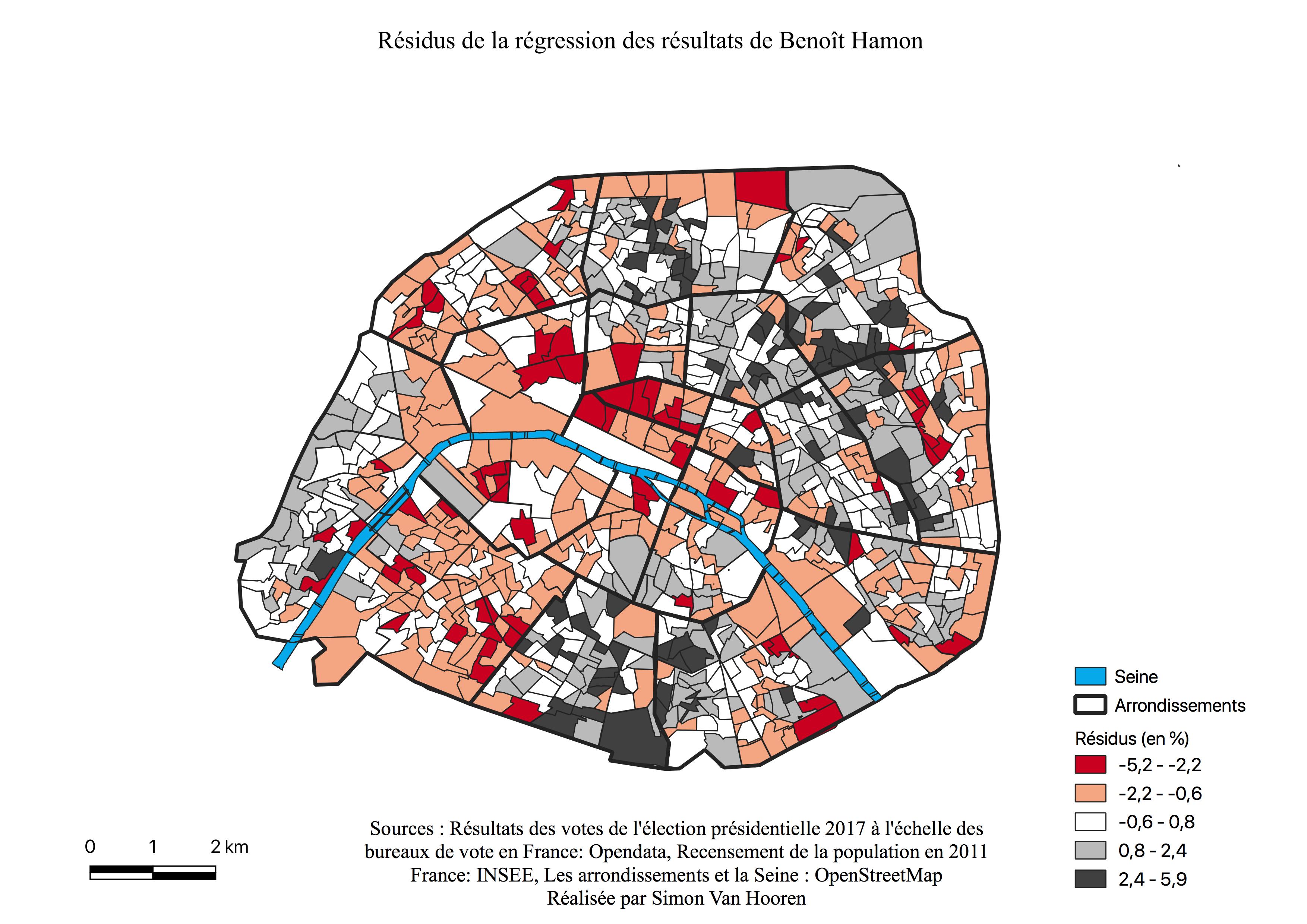
L’électorat de Benoît Hamon
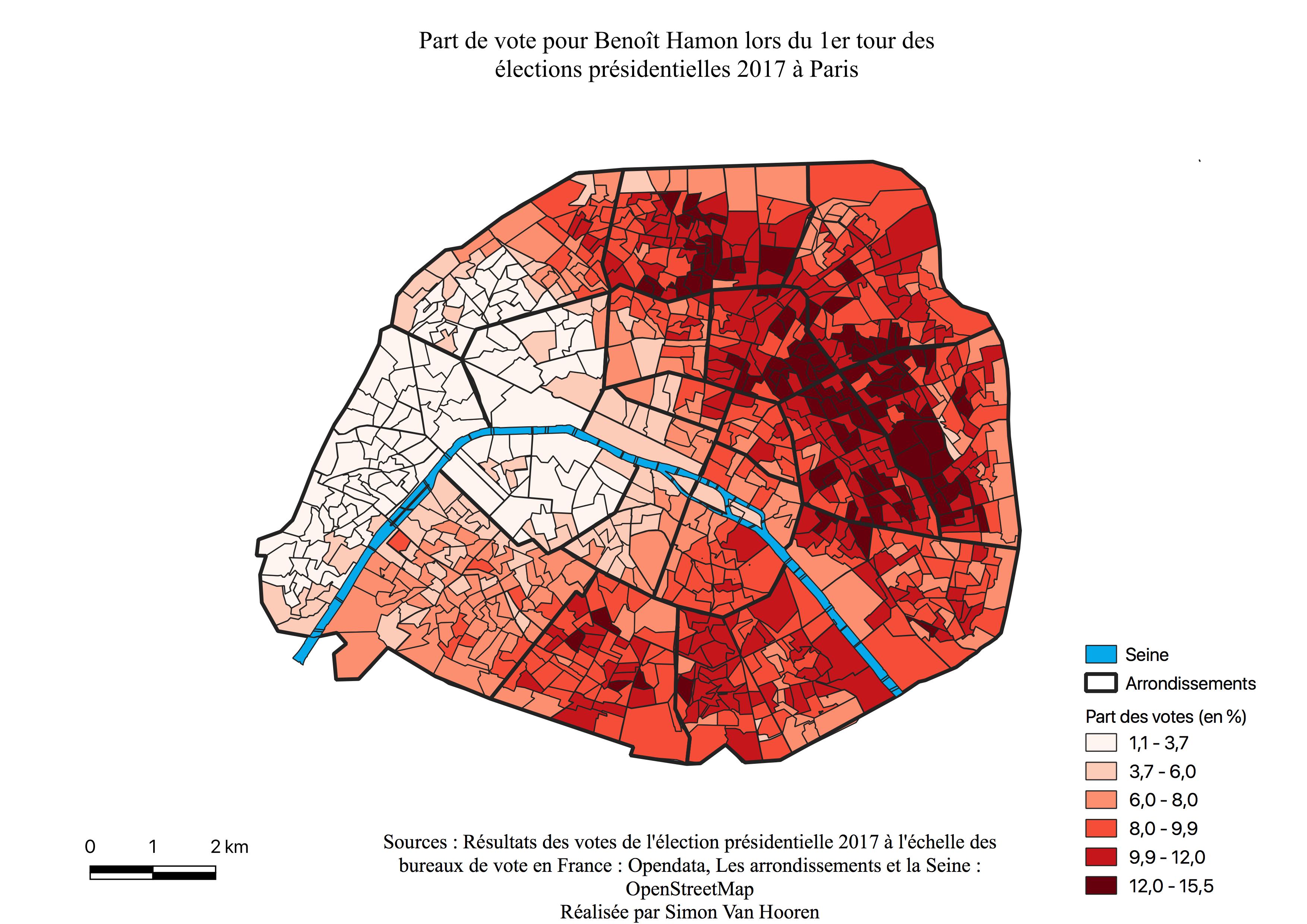
L’histogramme des résultats de Benoît Hamon est symétrique (voir Annexe \ref{H1H}), avec son sommet à 9%. La plupart des quartiers ont voté entre 6 et 12% pour ce candidat, mais malgré tout de nombreux quartiers ont voté pour lui entre 1,5 à 6%. Le candidat de la gauche traditionnelle perçoit peu de votes dans l’ensemble contrairement aux anciens candidats du Parti Socialiste.
La carte de l’électorat de Benoît Hamon (voir Figure \ref{C1H}) présente un gradient Est-Ouest. Ce gradient part du 18ème arrondissement, évolue en passant par les 10,11,12 et 20ème arrondissements et prend fin au sein des 13ème et 14ème arrondissements. Ses meilleurs scores, entre 12 et 16% sont à l’intérieur de ce croissant, au Nord et à l’Est mais les résultats diminuent sur les bordures. Le reste du croissant représente des votes entre 8 et 12%. La zone des hautes scores de François Fillon (voir Figure \ref{C1F}) vient parfaitement compléter les quartiers où Benoît Hamon est sous-représenté.
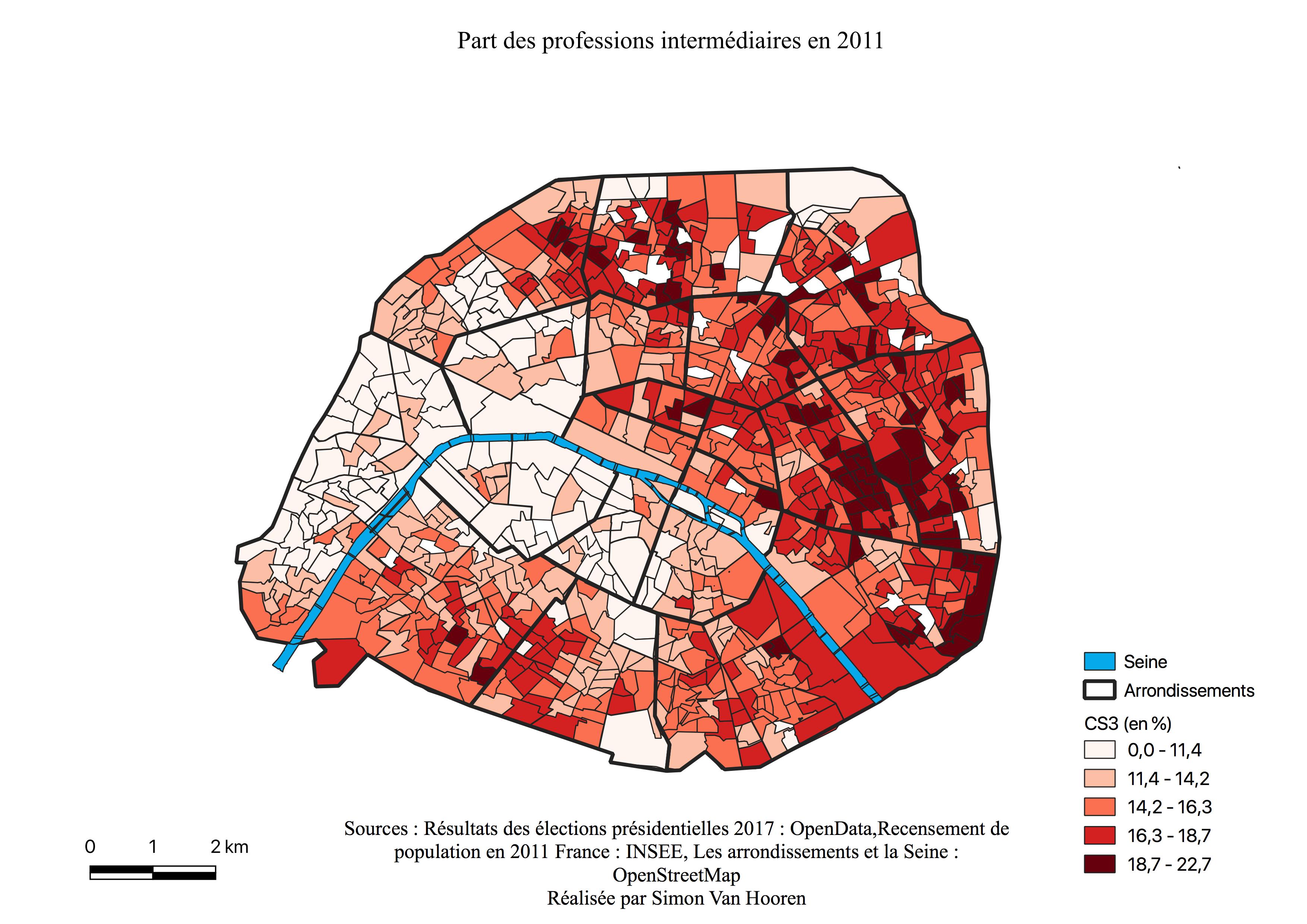
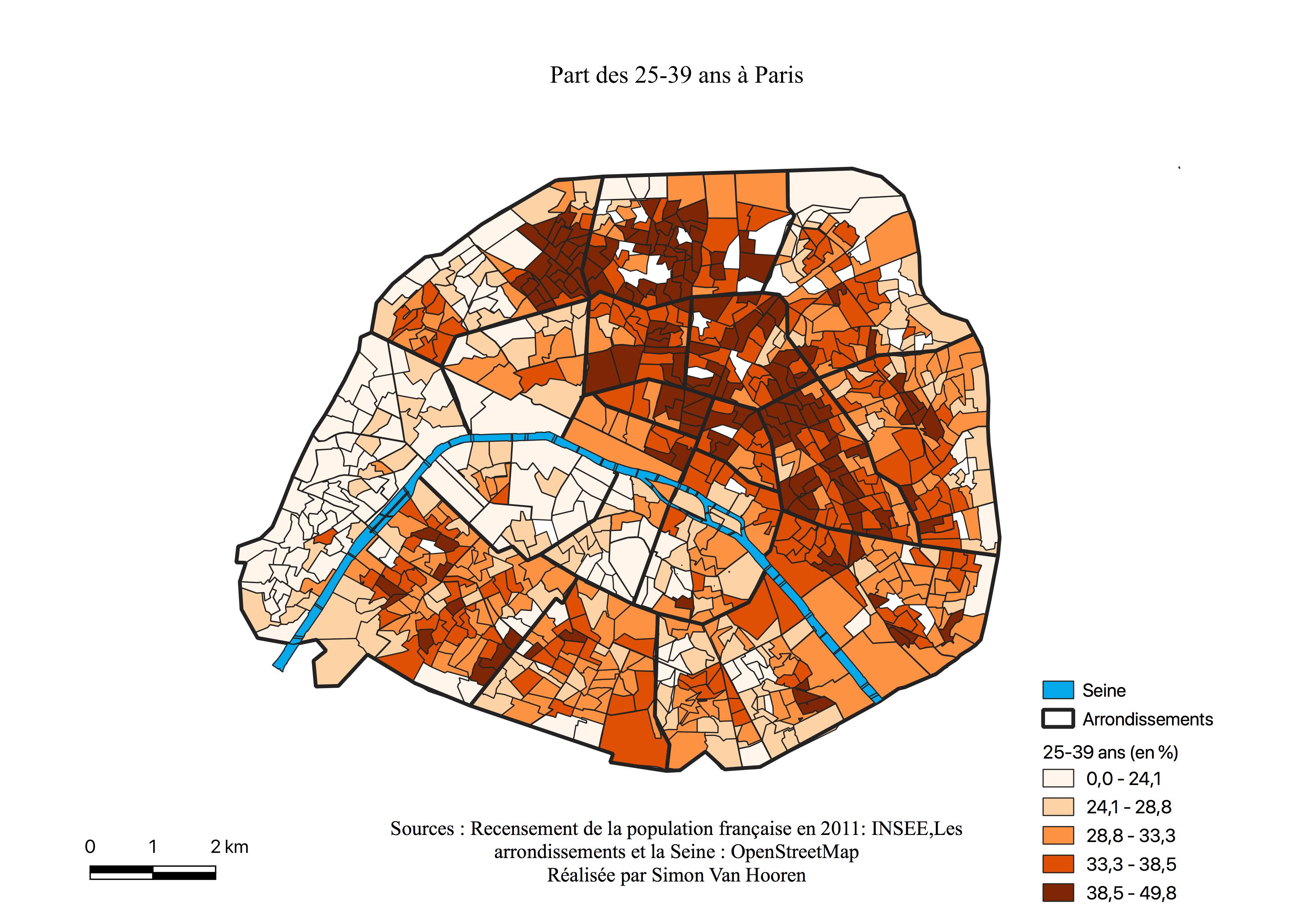
Une frontière marquée par la Seine apparaît au Sud de Paris, les votes pour Benoît Hamon sont majoritaires à l’Est et diminuent drastiquement à l’Ouest lorsque nous passons le cours d’eau. En analysant la carte, il semble que le vote pour Benoît Hamon soit relativement proche du centre, voir centré. Ajoutons aussi que la carte de son électorat ressemble à celle des professions intermédiaires (voir Annexe \ref{interm}) et des 25-39 ans (voir Annexe \ref{2539})
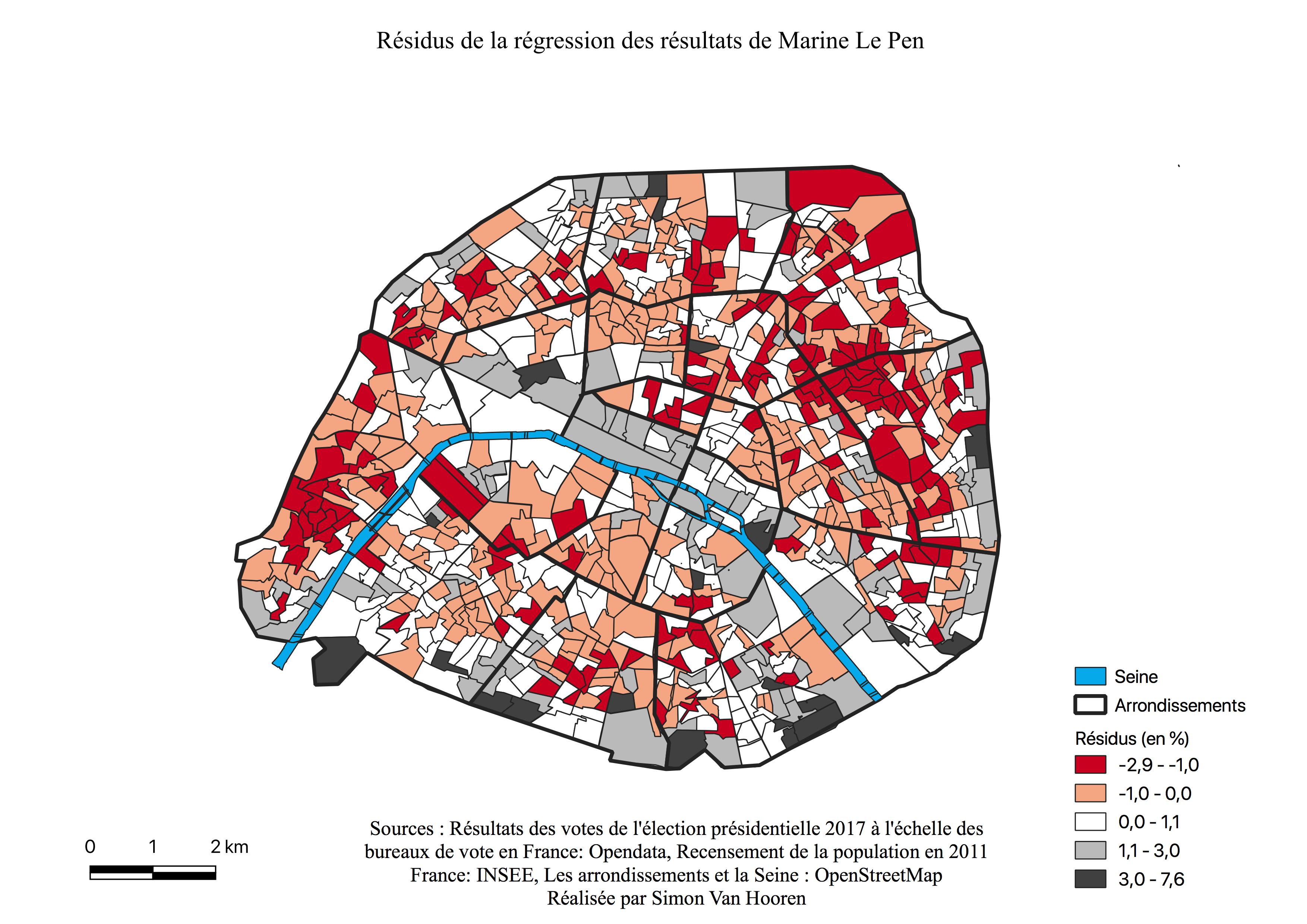
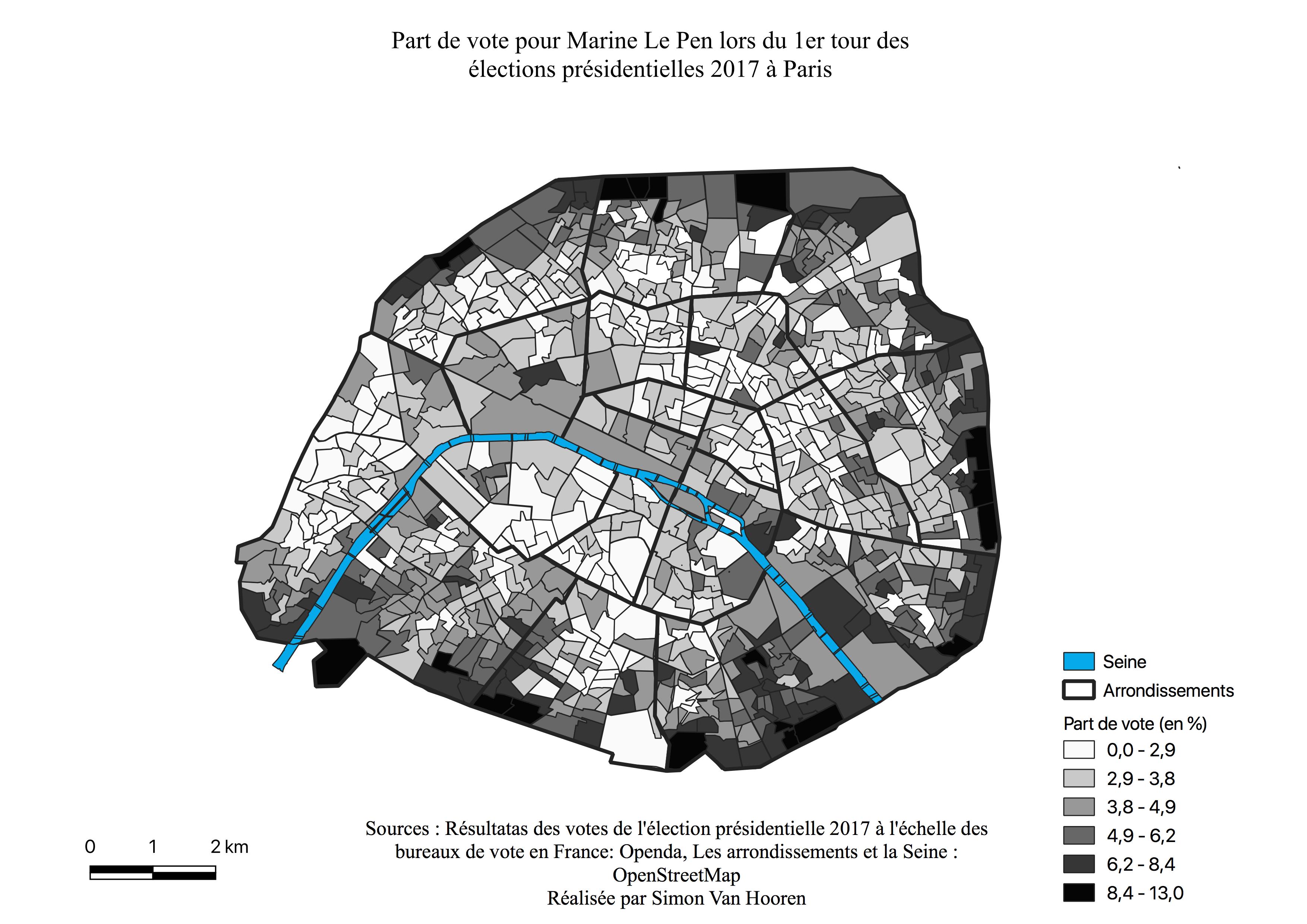
L’électorat de Marine Le Pen
L’histogramme de Marine Le Pen présente une distribution assymétrique à gauche (voir Annexe \ref{H1L}), la plus grande partie des quartiers ont des résultats faibles pour cette candidate, entre 2 et 5%. Notons que lorsque l’histogramme dépasse les 5% pour s’arrêter à 12%, il ne comprend qu’un très petit nombre de quartiers.
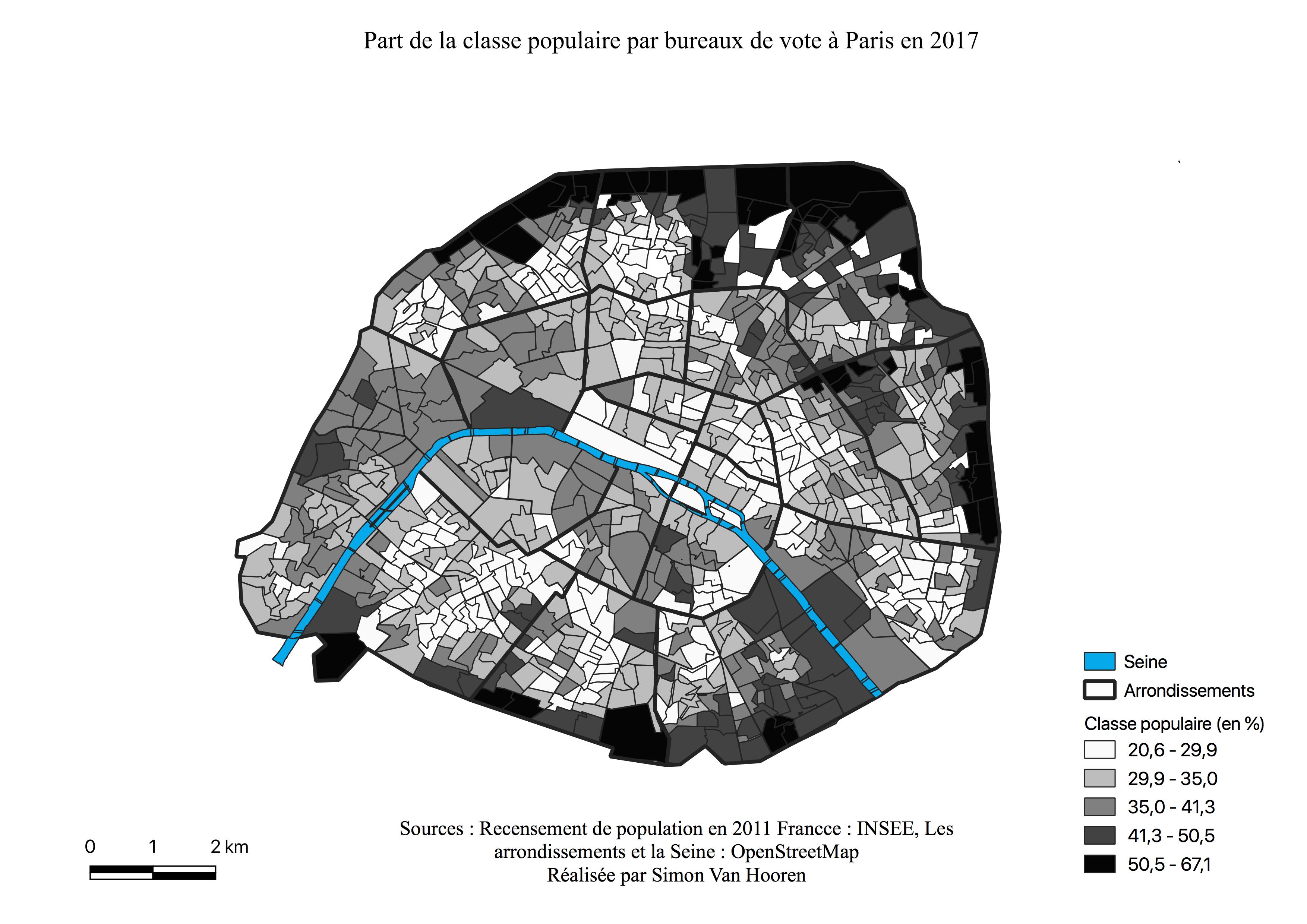
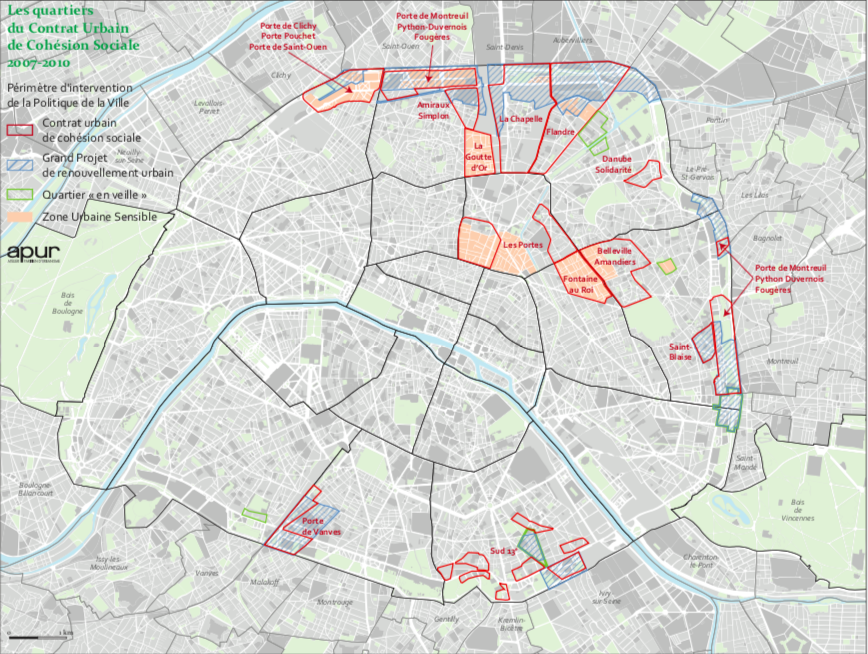
La géographie du vote pour Marine Le Pen (voir Figure \ref{C1L}) reprend pratiquement l’ensemble de la couronne de Paris, à l’exception de la bordure du 16ème arrondissement où sont regroupés les classes les plus aisées (voir Figure \ref{classessoc}). Sur les bordures, où elle réalise des scores moyens à élevés, nous retrouvons majoritairement les catégories socio-professionnelles moyennes inférieures et populaires (voir Figure \ref{classessoc}). La carte de la répartition de la classe populaire (voir Annexe \ref{popu}) ainsi que celle des Zones Urbaines Sensibles\footnote{Les zones urbaines sensibles (ZUS) sont des territoires infra-urbains définis par les pouvoirs publics pour être la cible prioritaire de la politique de la ville, en fonction des considérations locales liées aux difficultés que connaissent les habitants de ces territoires.(INSEE)} (ZUS) (voir Figure \ref{zus}) semblent appuyer le caractère populaire de l’électorat pour Marine Le Pen. En effet, là où les votes sont les plus élevés pour la candidate, se situe une Zone Urbaine Sensible ou un Contrat de Cohésion Urbain Social (CUCS), zone de surreprésentation des employés, ouvriers et sens emplois.
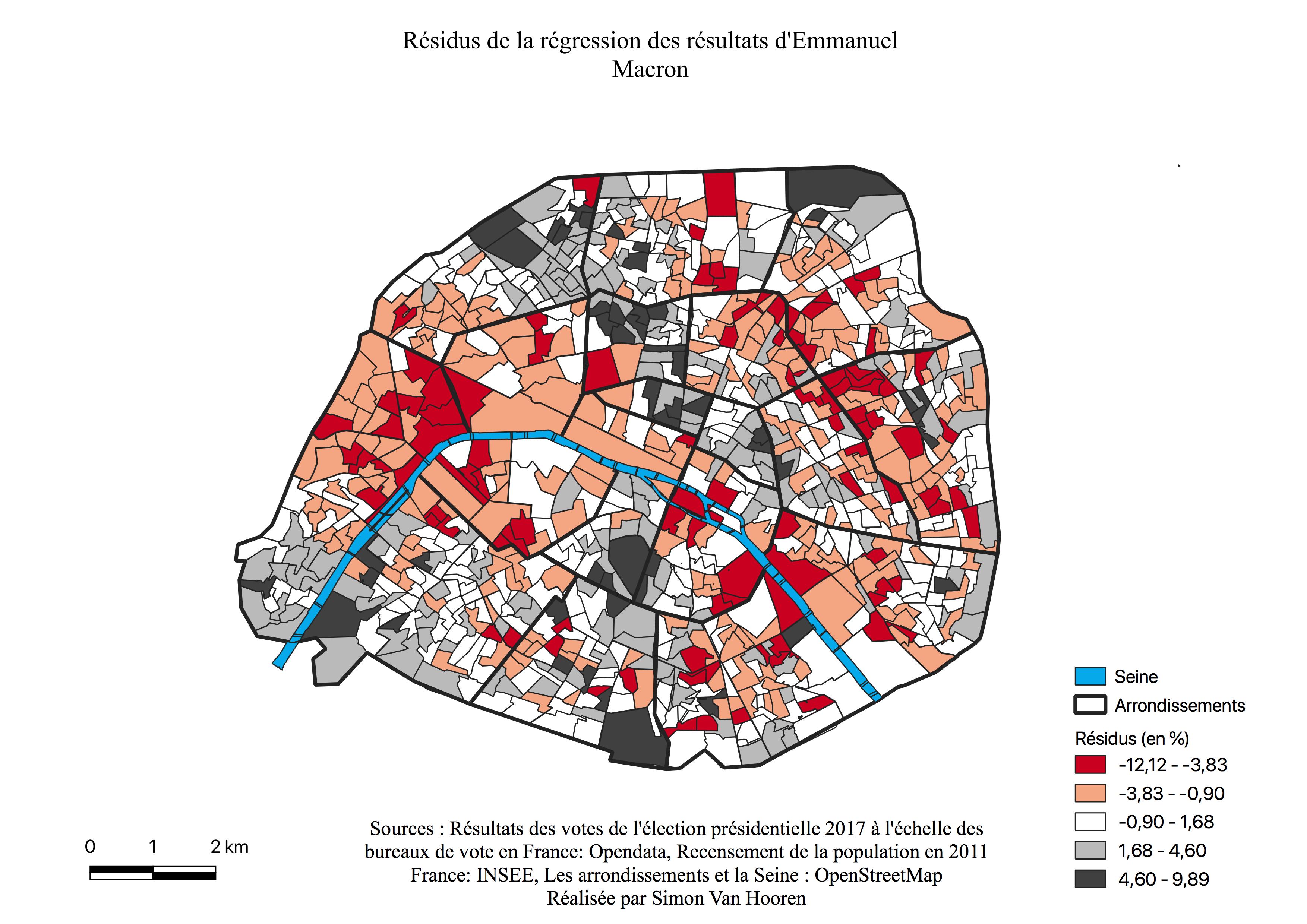
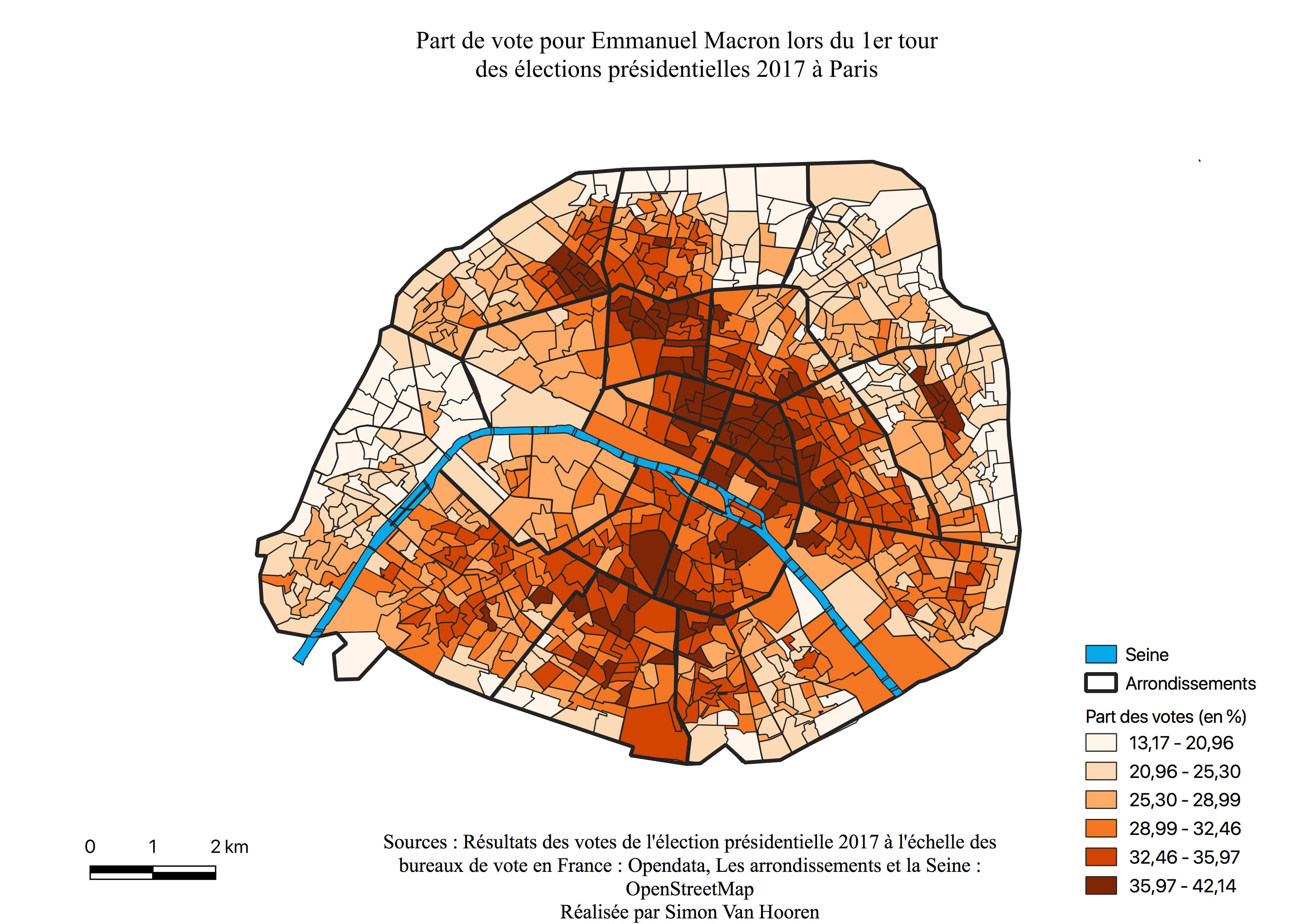
L’électorat d’Emmanuel Macron
Emmanuel Macron possède une distribution (voir Annexe \ref{H1EM}) des résultats de vote assez symétrique quoique légèrement tirée vers la droite. Les valeurs extrêmes possèdent malgré tout un grand nombre d’observations et la majorité d’entre elles se situe entre 25% et 36%, montrant que ce candidat détient de hauts scores sur l’ensemble des quartiers de Paris. Ceux ayant le moins voté pour lui présentent malgré tout des pourcentages allant de 15 à 20%. Pour obtenir un tel histogramme il faut qu’il représente soit un vote interclassiste soit une classe sociale majoritaire.
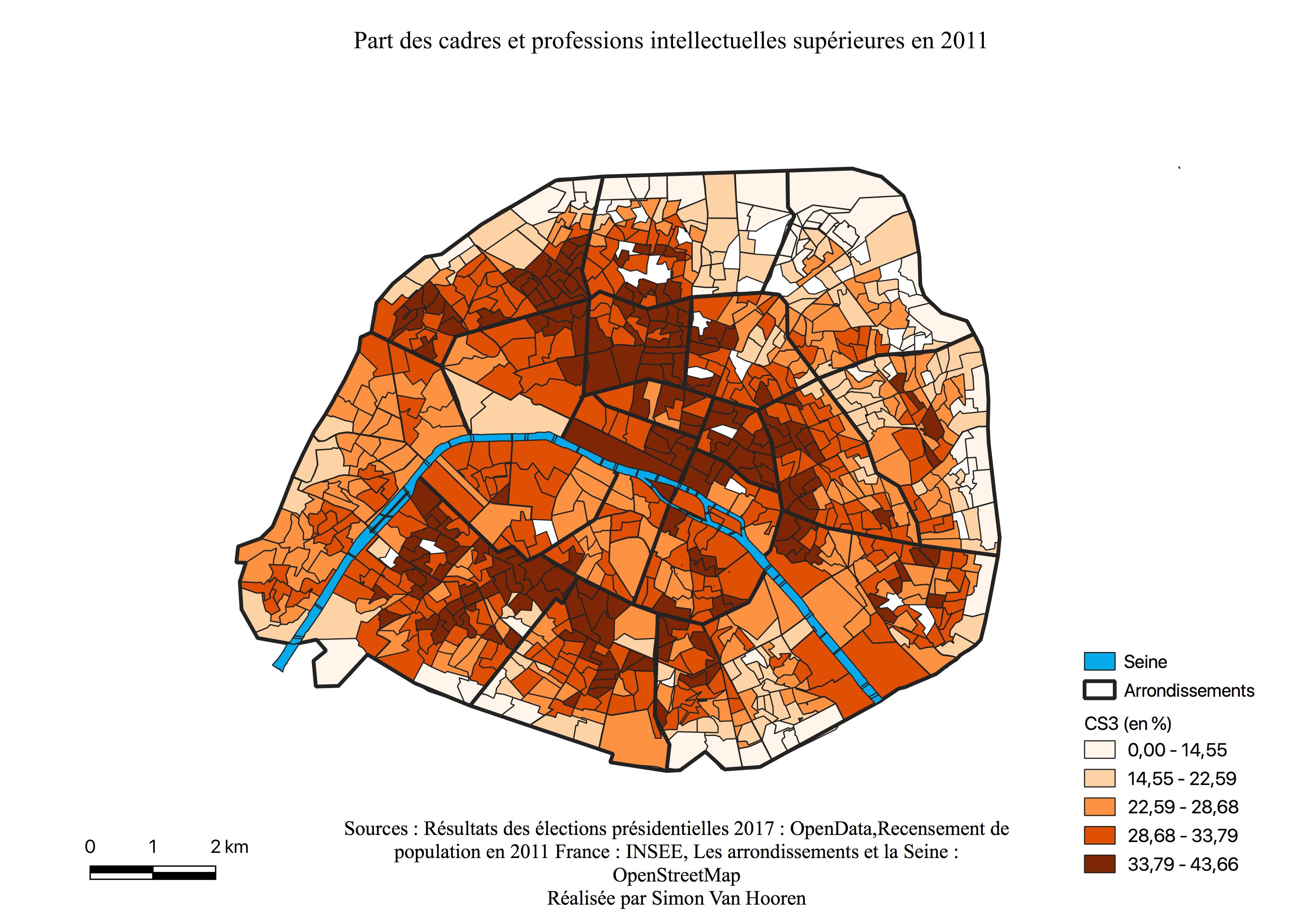
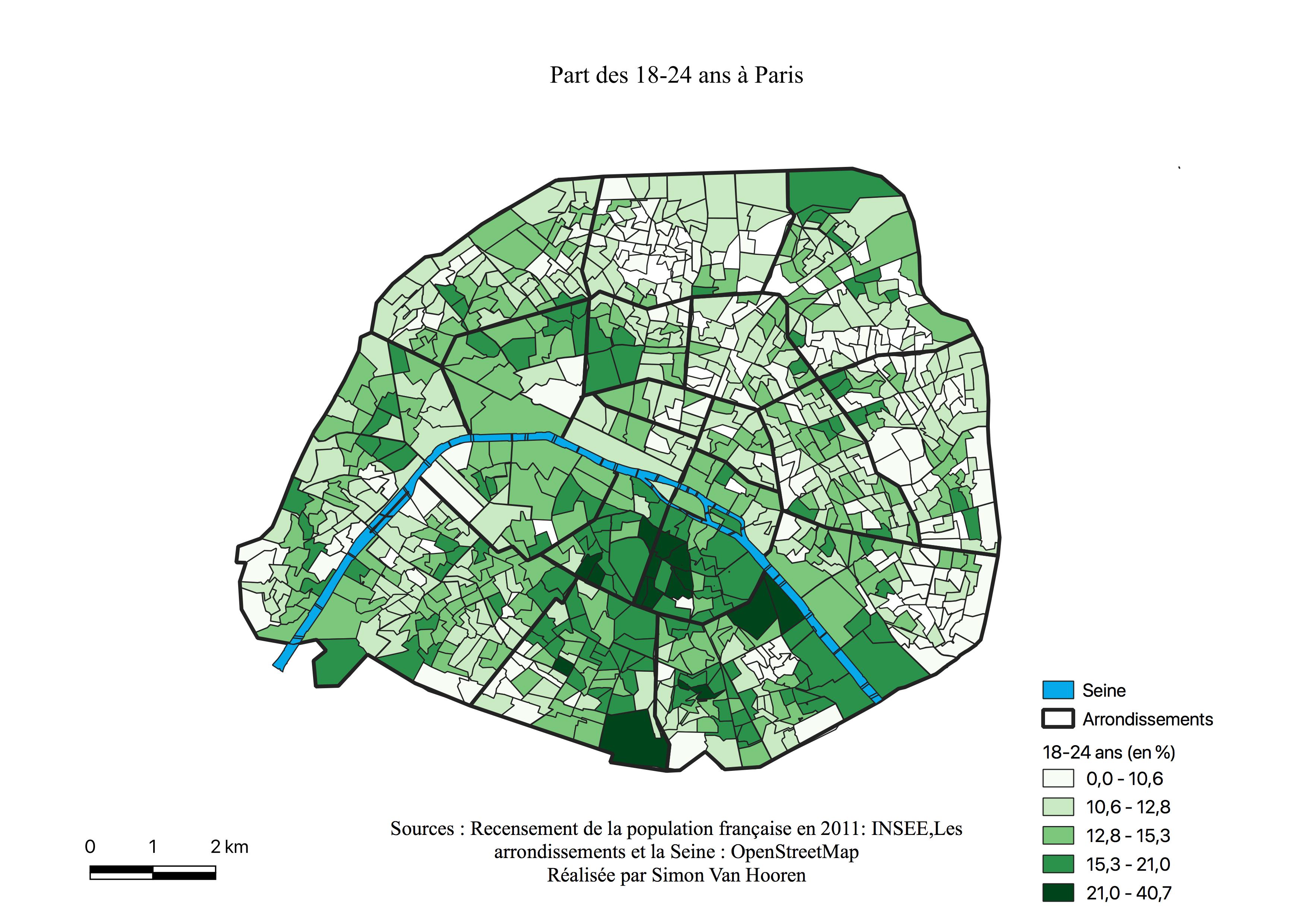
La carte des résultats pour Emmanuel Macron (voir Figure \ref{C1EM}) indique un vote élevé généralisé à l’exception des périphéries. Remarquons que les quartiers en blancs signifie un vote entre 13 et 21%. Le centre représente ses quartiers les plus favorables. Une “ligne” de concentration des votes élevés (36 à 42%) suit les 17ème - 9ème - 2ème - 3ème arrondissements et semble correspondre aux lieux de surreprésentation des 25-39 ans, des cadres et des professions intellectuelles supérieures au sein de leurs cartes respectives (voir Annexes \ref{2539},\ref{CS4}). Une autre zone de concentration des hauts pourcentages se situe dans les quartiers du Sud des 5ème et 6ème arrondissements, où sont surreprésentés les cadres et professions intellectuelles supérieures à nouveau ainsi que les jeunes de 18 à 24 ans (voir Annexe \ref{1824}).
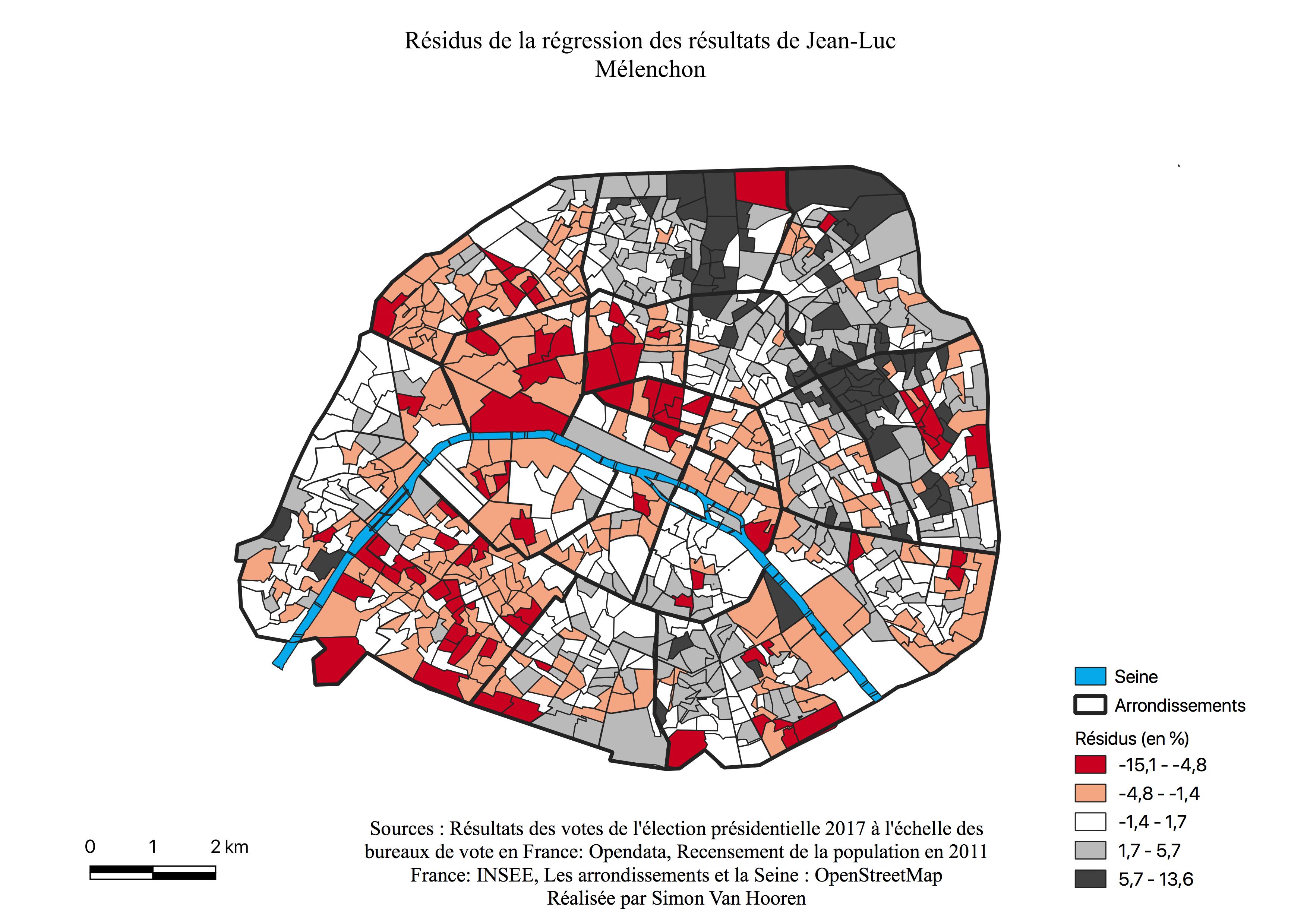
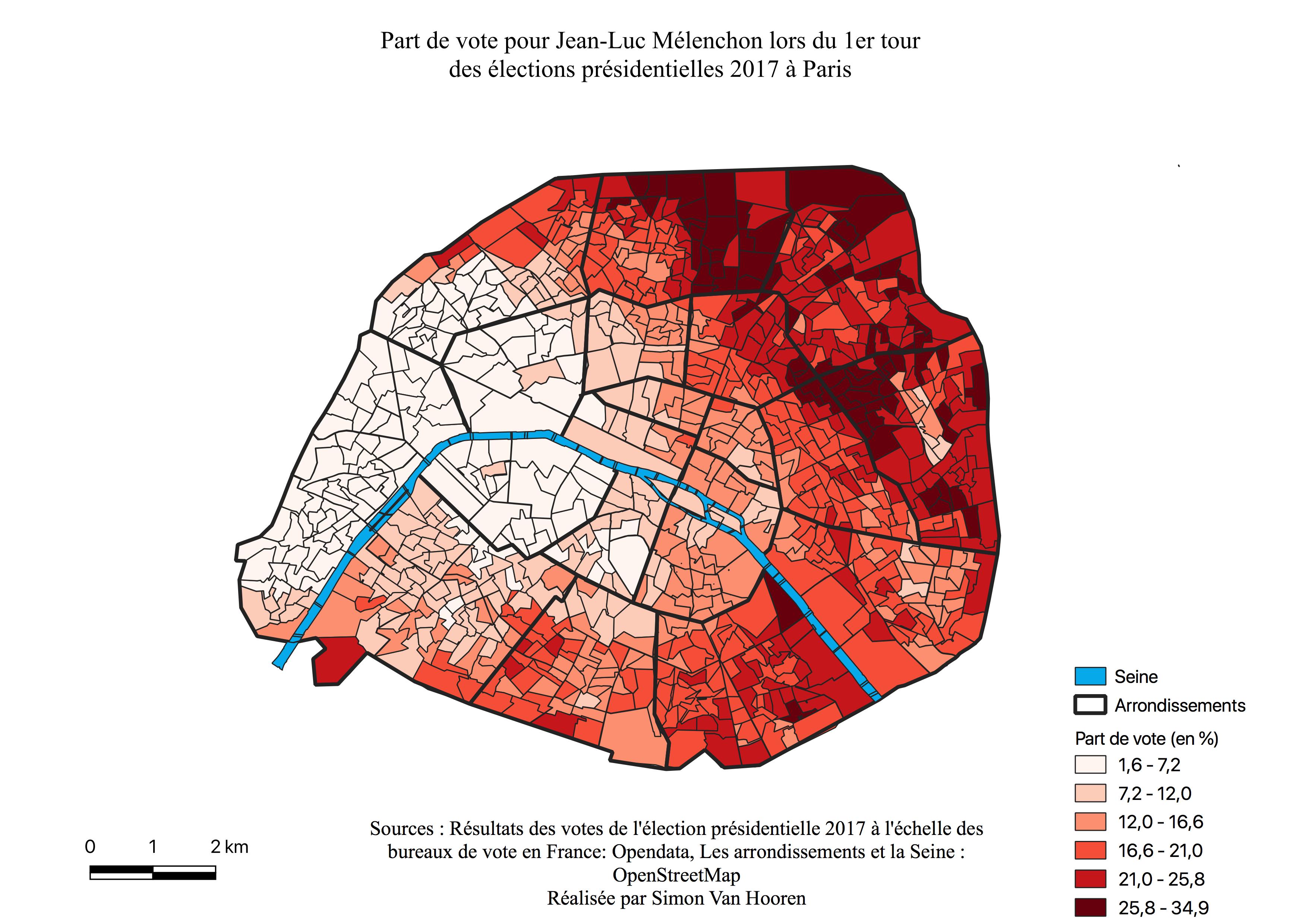
L’électorat de Jean-Luc Mélenchon
En analysant l’histogramme de Jean-Luc Mélenchon (voir Annexe \ref{H1M}), on constate le caractère multimodal de la distribution, un grand nombre de quartiers ont voté pour lui à différents pourcentages. La majorité des résultats se situe entre 3 et 25%, il s’agit d’un spectre plus large que les autres candidats. De plus le nombre de bureaux diminuent au delà de 25%.
Les résultats de vote pour Jean-Luc Mélenchon (voir Figure \ref{C1M}) se présentent, à l’instar de Benoît Hamon (voir Figure \ref{C1H}), en un gradient Est-Ouest. Les scores sont cependant plus élevés pour ce candidat, ils sont entre 21 et 35%, et sont également plus marqués en périphérie du croissant alors que Benoît Hamon réalise ses meilleurs scores à l’intérieur de celui-ci. Constatons à nouveau les pourcentages les plus faibles dans les quartiers bourgoies où François Fillon réalise ses meilleurs scores et où les catégories aisées sont les plus présentes (voir Figure \ref{C1F}, Annexe \ref{aises}). Jean-Luc Mélenchon connaît un survote au sein des 18ème, 19ème et 20ème arrondissements, lieux de concentrations des classes sociales défavorisées (voir Annexe \ref{popu}), des ZUS et CUCS (voir Figure \ref{zus}).
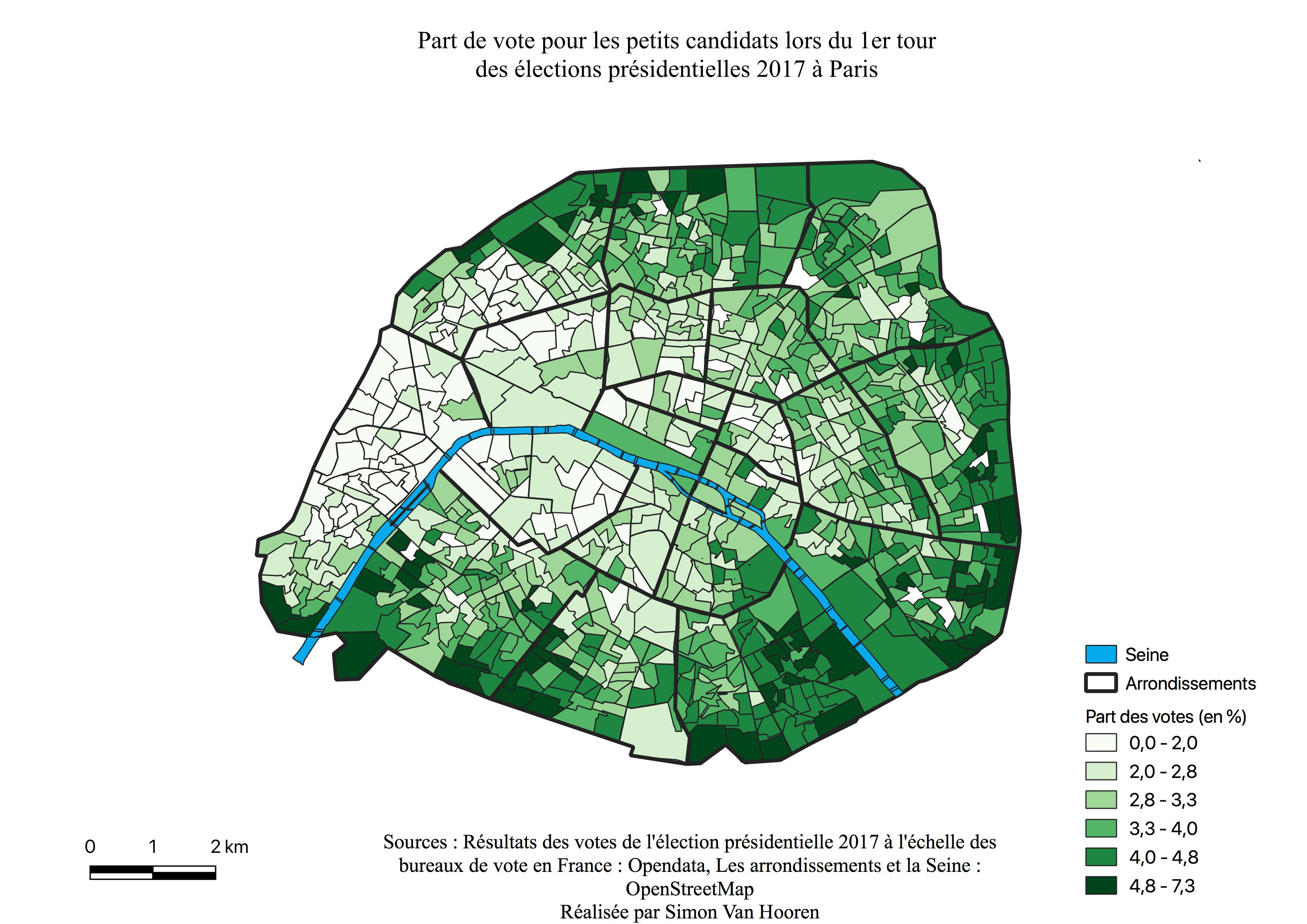
L’électorat des petits candidats
L’histogramme des petits candidats (voir Annexe \ref{H1PC}) a une distribution symétrique et la majorité des valeurs sont comprises entre 2 et 5%. Certains quartiers ont voté pour les petits candidats jusqu’à 7%.
Les petits candidats ne jouent pas un rôle important au sein de la géographie électorale à moins d’avoir une géographie spécifique. Dans le cadre de ces élections, il existe bel et bien une géographie des petits candidats (voir Figure \ref{C1PC}), celle-ci suit le même croissant que pour les électorats de Jean-Luc Mélenchon (voir Figure \ref{C1M}) et Benoît Hamon en moindre mesure (voir Figure \ref{C1H}).
\begin{table}[h]
\scriptsize
\begin{tabular}{llllll}
term & estimate & std.error & statistic & p.value &
(Intercept) & 1.85250340706787 & 0.675893281971995 & 2.74082234056681 & 0.00625303982737119 & **
Petits_candidats & 4.26362937966758 & 0.197648289039292 & 21.5718000919299 & 3.79706965594979e-83 & ***
\end{tabular}
\caption{Régression entre les résultats des petits candidats et ceux de Jean-Luc Mélenchon}
\label{tab:regpetitsmel}
\end{table}
Ces géographies similaires entre Jean-Luc Mélenchon et les petits candidats amènent à se poser la question d’un possible lien entre leurs électorats. Une analyse par régression linéaire simple entre les résultats des petits candidats et les résultats de Jean-Luc Mélenchon permet d’affirmer qu’ils sont bels et bien liés (voir Table \ref{tab:regpetitsmel}).
Le second tour
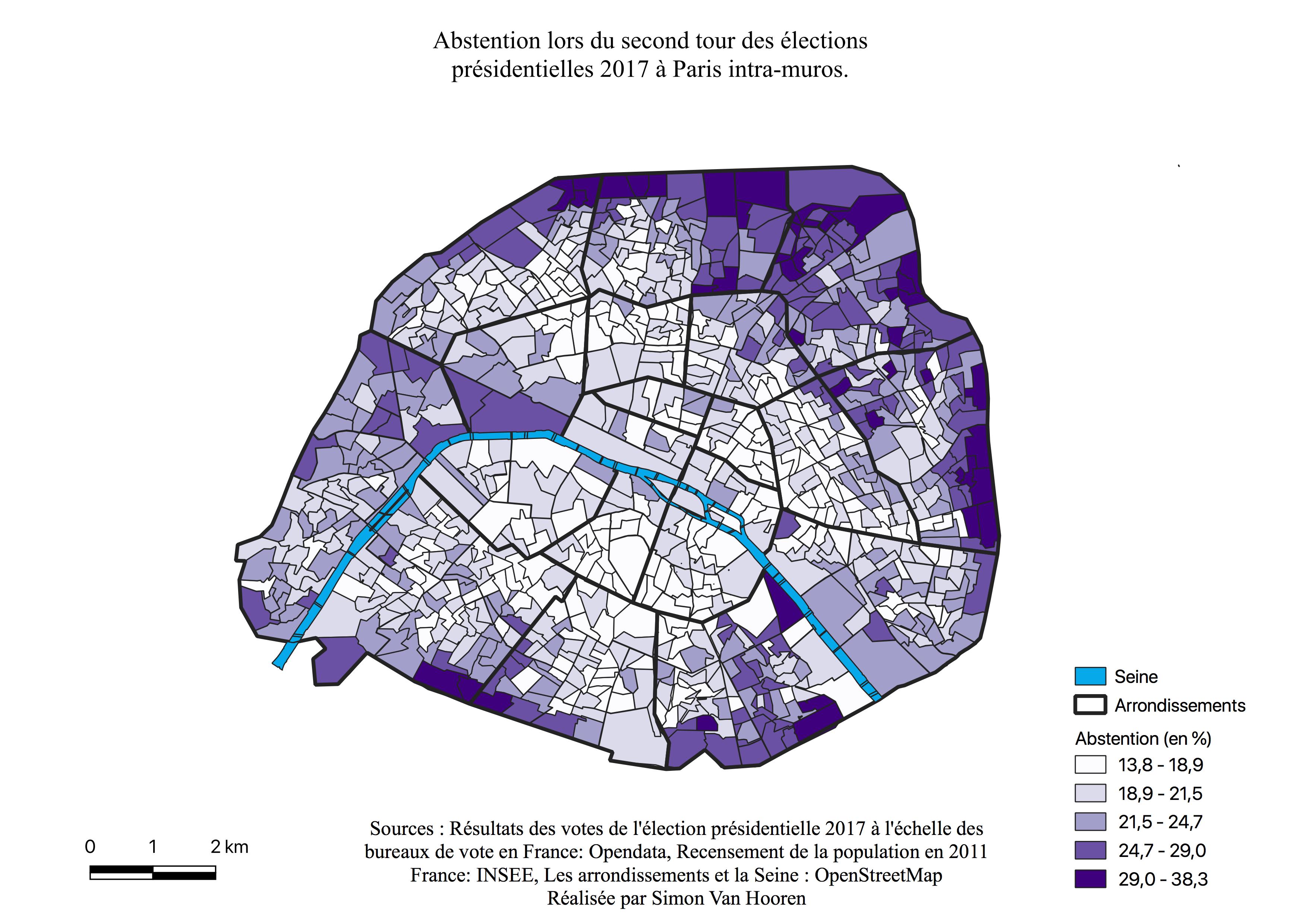
La géographie de l’abstention lors du second tour
En analysant l’abstention de ce second tour, nous remarquons qu’elle convers la même géographie à l’exception du Nord des beaux quartiers qui gagne près de 10%. En comparaison avec le 1er tour, l’abstention connaît un gain de plus de 2% et ce dans pratiquement tous les quartiers de Paris.
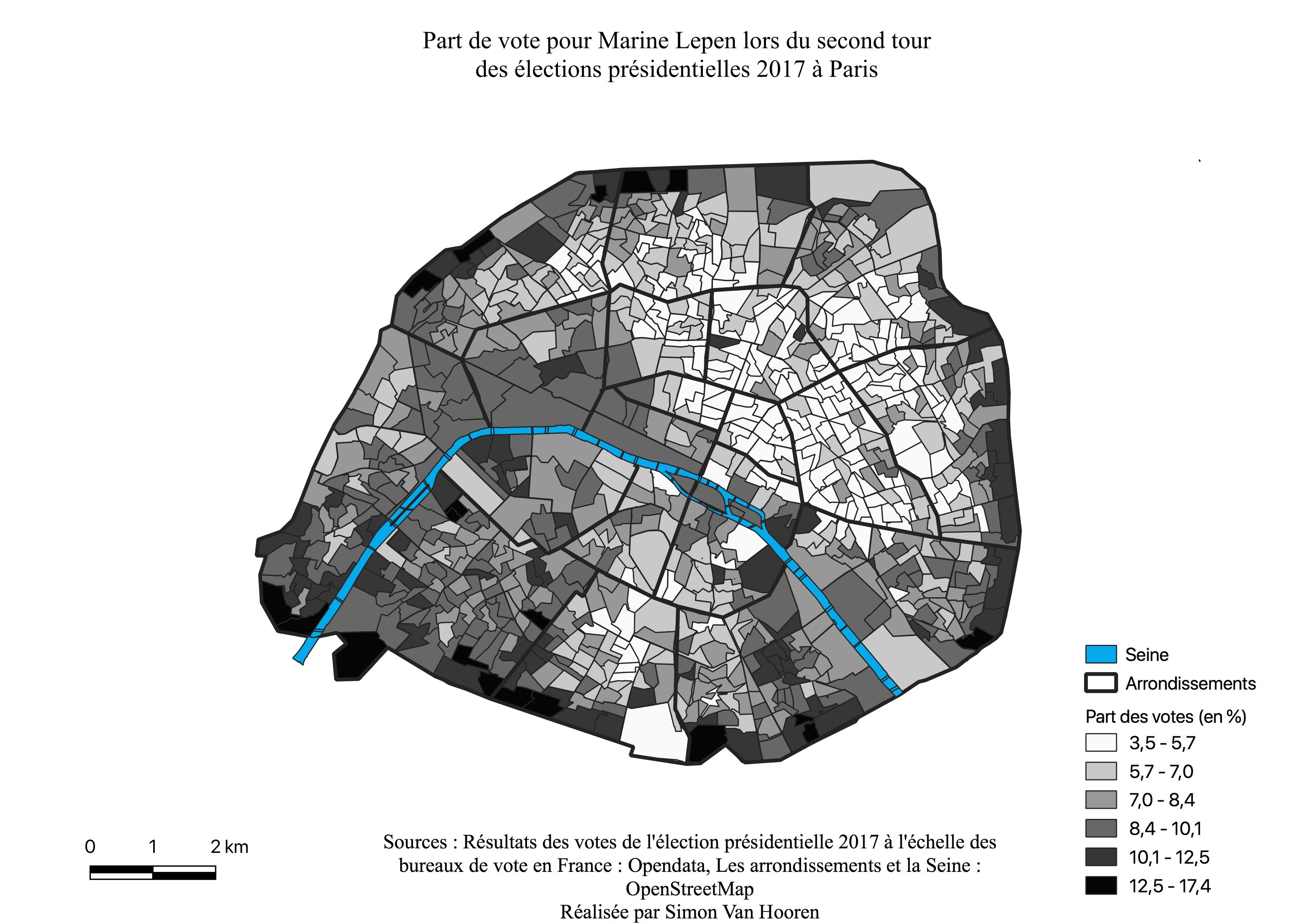
Marine Le Pen
Le second tour se déroule entre la candidate d’extrême droite Marine Le Pen et le candidat centre droit Emmanuel Macron.
L’histogramme de Marine Le Pen pour ce second tour, est assymétrique à gauche (voir Annexe \ref{H2M}), la majorité des résultats sont compris entre 5 et 10%. En le comparant à celui du premier tour (voir Annexe \ref{H1L}), l’augmentation apparaît très nettement, la plupart des quartiers ayant voté pour elle se situent uniquement entre 2 et 5%. De même, ses résultats les plus forts sont cette fois entre 12 et 17 %, contre 8 à 12% lors du premier tour.
La carte des résultats de Marine Le Pen (voir Annexe \ref{C2L}) lors du second tour garde la même zone de survote en périphérie, mais gagne du terrain vers le centre à l’Ouest et au Sud de Paris en partant de la Seine. En périphérie les scores varient entre 8 et 17%. De la périphérie Ouest et Sud vers le centre les scores sont entre 6 et 10%, ce qui représente une nette évolution pour la candidate. A l’Est la mosaïque plus importante de quartiers ayant voté entre 3 et 6% pour la candidate sont repris dans l’histogramme. La carte de l’électorat de Marine Le Pen ressemble très fortement à celle des classes populaires (voir Annexe \ref{popu}) mais semble également avoir conquis de manière plus franche quelques quartiers aisés (voir Figure \ref{C1L},Annexe \ref{aises}).
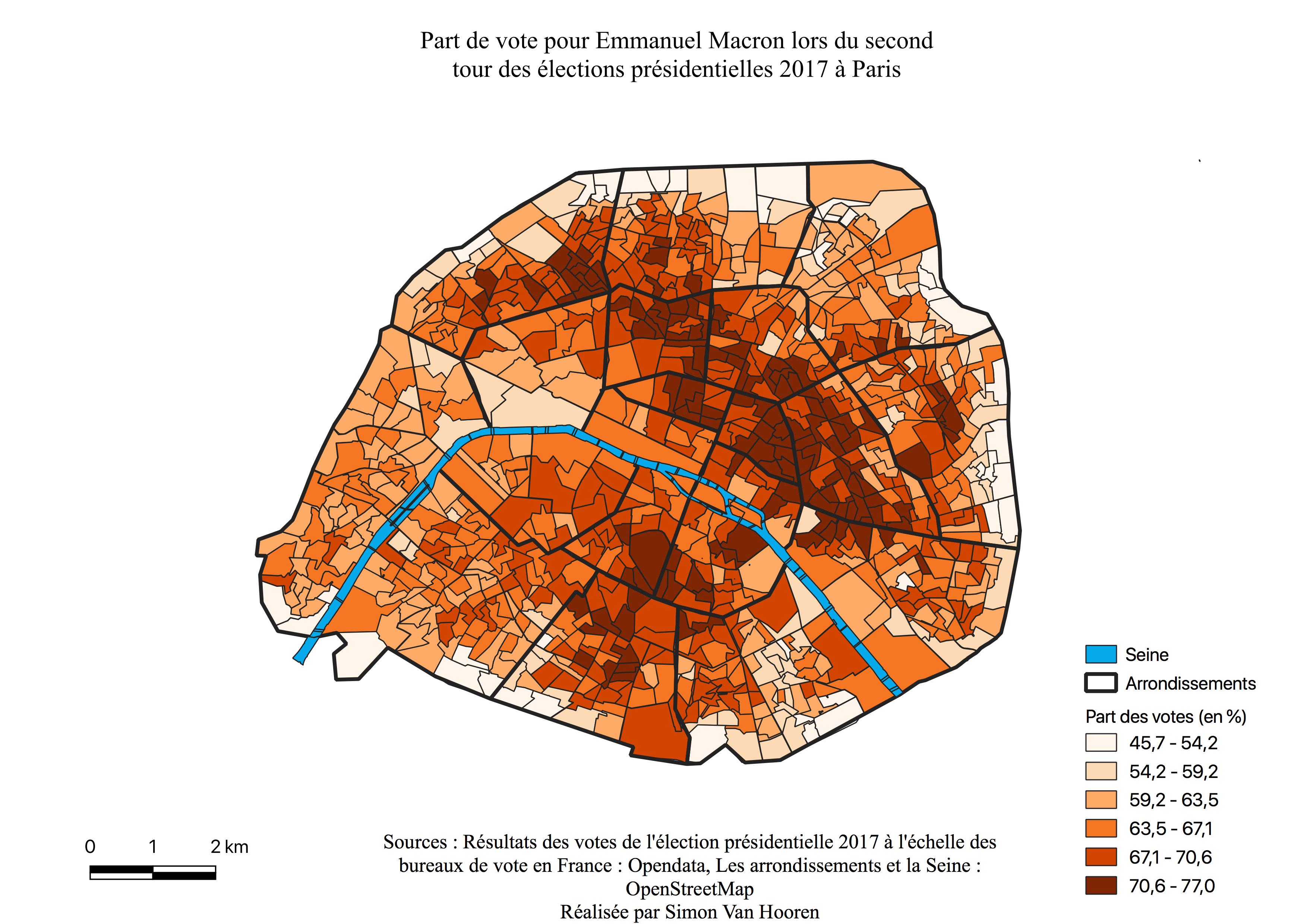
Emmanuel Macron
L’histogramme d’Emmanuel Macron (voir Annexe \ref{H2M}) lors de ce second tour montre sa supériorité face à la candidate d’extrême droite. La distribution est ici symétrique à droite, la majorité de ses résultats se situe entre 60 et 73 %. Toutefois, il convient de se rappeler que l’abstention était plus élevée à ce tour-ci. L’histogramme du second tour comparé à celui du 1er tour (voir Annexe \ref{H1EM}) indique une nette évolution de ses scores lors du 2ème scrutin, mais également que beaucoup plus de quartiers ont voté de manière plus forte pour Emmanuel Macron.
La carte de l’électorat d’Emmanuel Macron (voir Annexe \ref{C2M}) est très homogène, sauf en périphérie, zone de survote pour Marine Le Pen, indiquant le caractère centré de l’électorat de ce candidat. Malgré tout, les quartiers ayant le moins voté pour lui offrent des scores de près de 50%. Les arrondissement qui avaient les plus hauts scores en sa faveur sont les mêmes qu’au premier tour, mais avec 20% de plus à ce tour-ci, et ils sont à nouveau sur la même ligne discutée en \ref{Cartm} qui s’est élargie et allongée. La carte ressemble à celle des classes intermédiaires (voir Annexe \ref{interm}) et présente pratiquement la même géométrie que celles des cadres et professions intellectuelles supérieures (voir Annexe \ref{CS3}). En effet, sur cette dernière la bordure à l’Est est plus claire alors qu’à l’Ouest les pourcentages restent élevés.
Résultats de l’Analyse en composantes principales
Au sein de ce travail les variables intégrées dans l’analyse en composantes principales sont les résultats des différents candidats par bureau de vote auxquels nous superposons les variables quantitatives supplémentaires : les catégories sociales. Le système d’axes qui en ressort offre la possibilité de placer les candidats selon les différentes composantes principales et de les situer par rapport aux classes sociales. Attention, l’Analyse en Composantes Principales ne permet pas de tirer des conclusions sur des possibles liens entre les variables introduites et les variables supplémentaires puisque deux points proches sur un axe ne le sont peut-être pas dans un autre système d’axes, pour tirer de telles conclusions le seul outil reste les régressions. Elle n’est qu’une simplification de l’espace électoral, une réduction de l’information en replaçant sur un nouveau système d’axes les résultats par candidats des bureaux de vote.
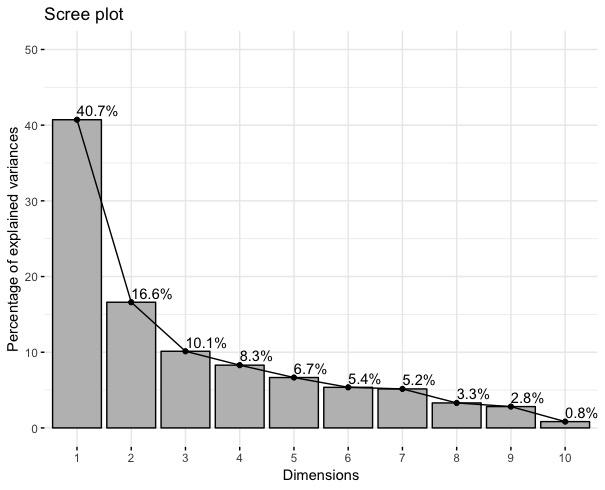
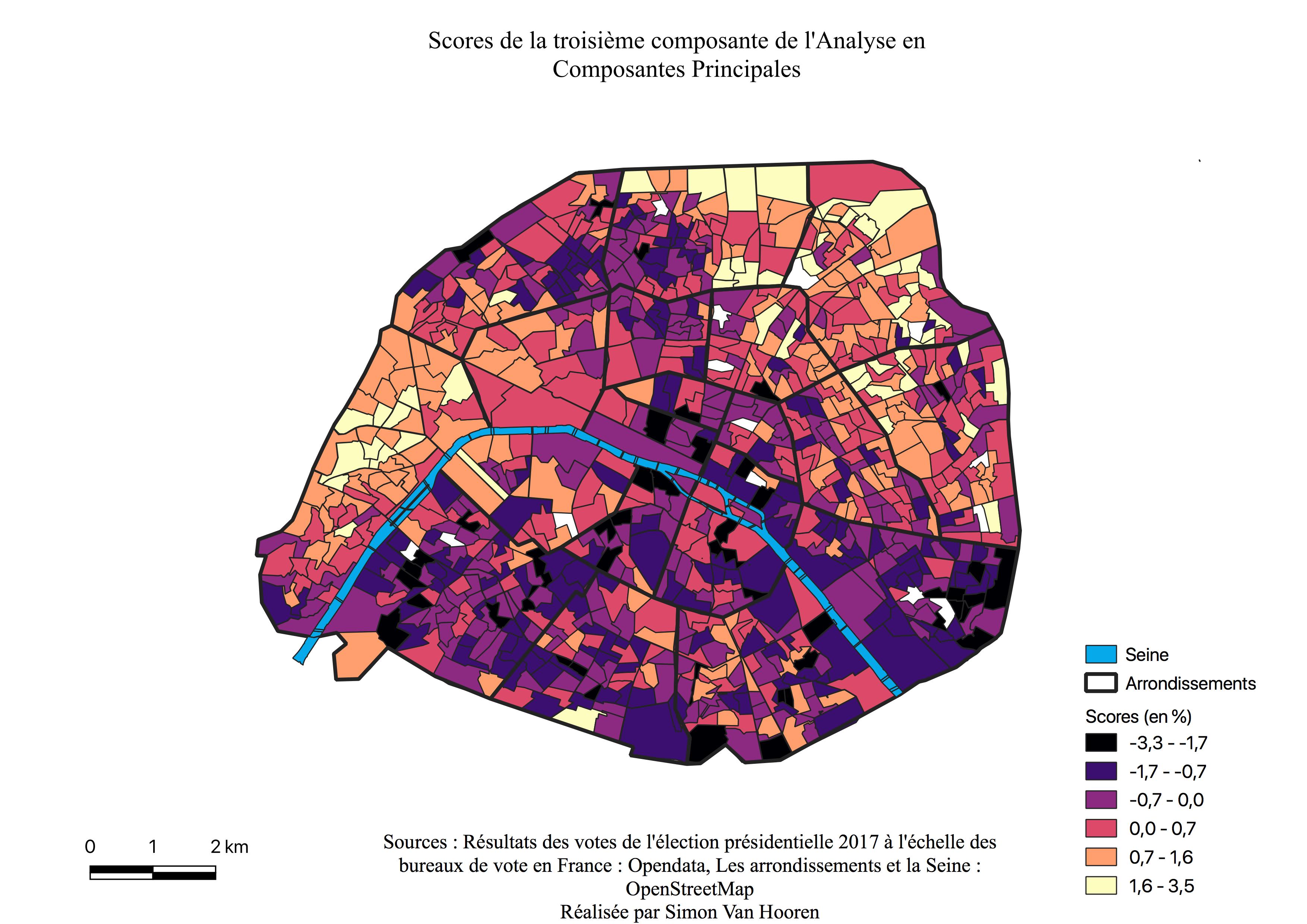
Avant toute analyse du graphique des composantes, nous observons la portion de variance captée par chaque composante sur le screeplot de l’analyse en composantes principales. Comme nous pouvons le constater sur le graphique (voir Figure \ref{scree}), les trois premières composantes expliquent 67% de la variance totale tandis que les suivantes en expliquent une beaucoup plus petite part.
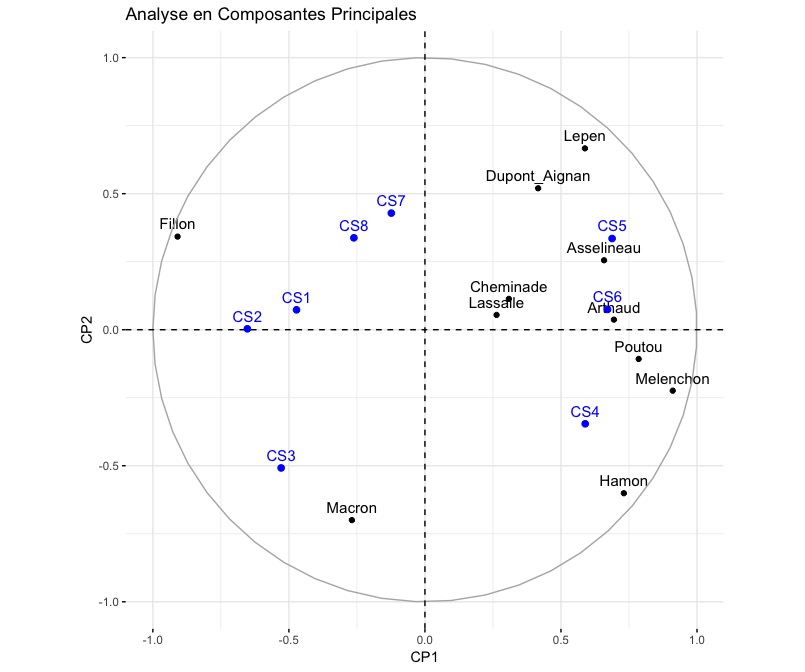
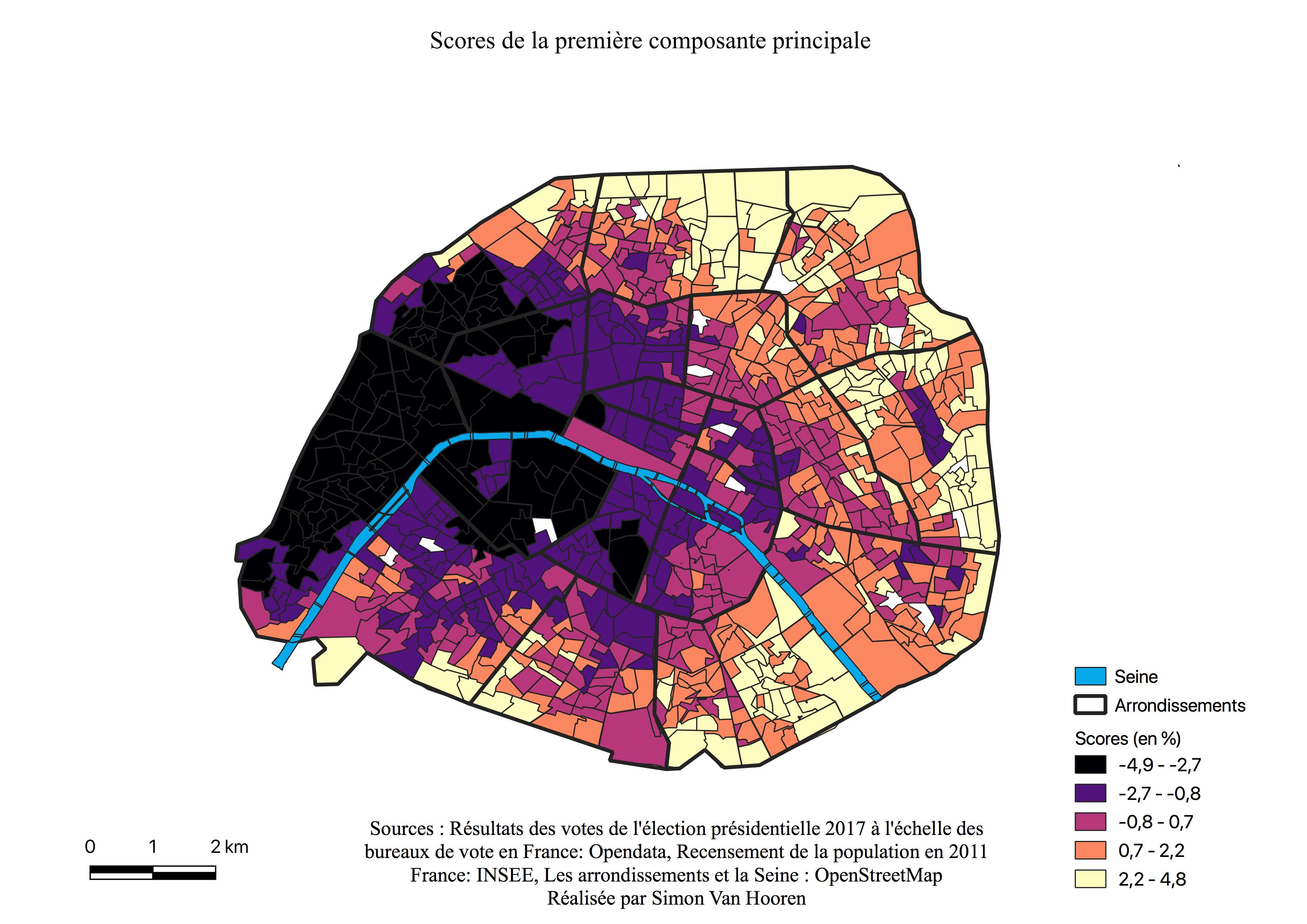
La première composante principale (voir Figure \ref{ACP1}) lie Emmanuel Macron avec Benoît Hamon et d’autre part elle les oppose à François Fillon, Marine Le Pen et Nicolas Dupont-Aignan. De manière beaucoup moins significative, Jean-Luc Mélenchon est représenté du côté de Benoît Hamon et Emmanuel Macron tandis que François Asselineau est plus proche de Marine Le Pen, Nicolas Dupont-Aignan et François Fillon. Enfin les candidats Jean Lassalle, Nathalie Arthaud et Philippe Poutou sont trop proches de l’axe que pour réaliser une analyse correcte. Ce premier axe oppose les classes moyennes aux autres classes sociales.
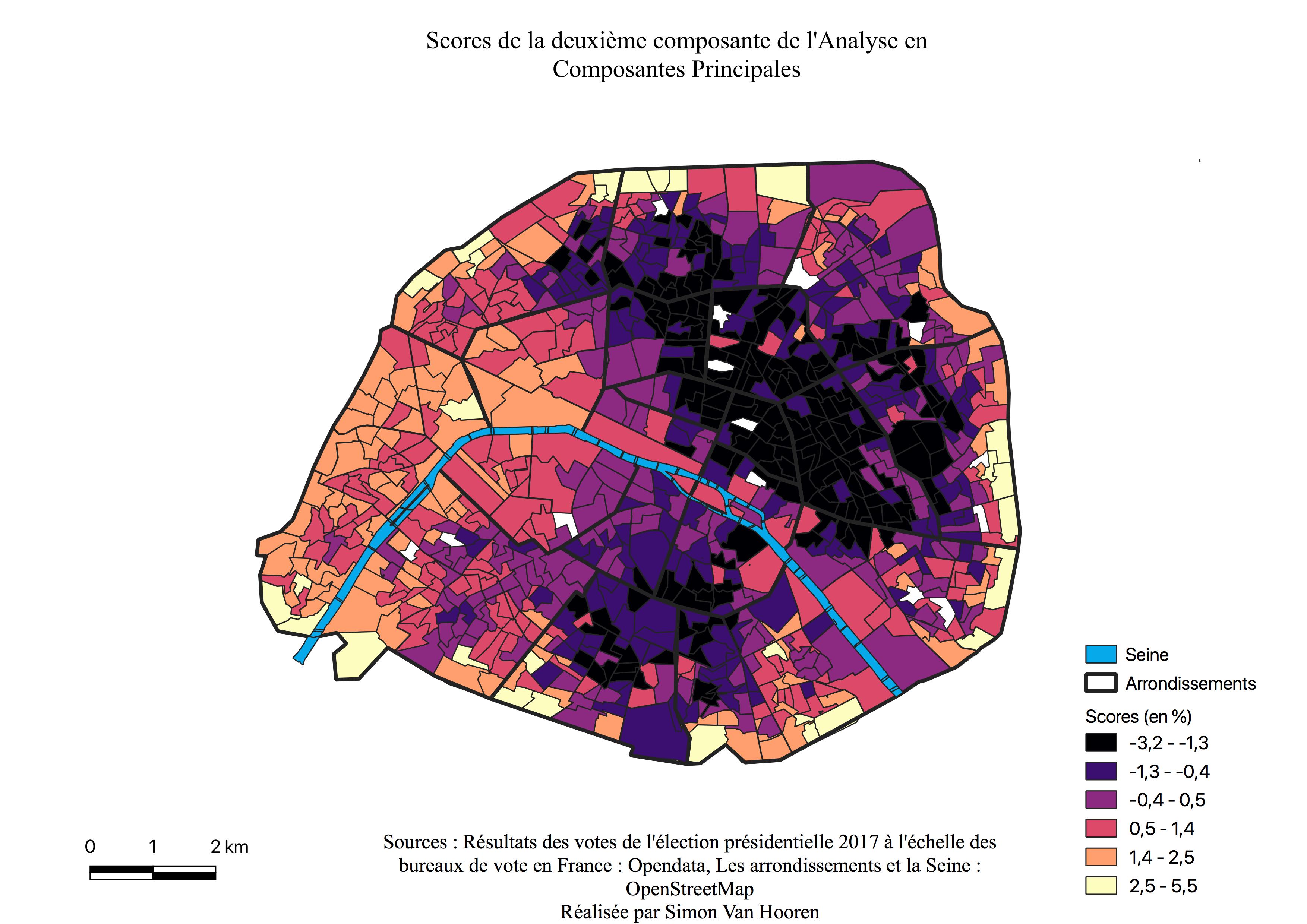
Le second axe offre une nette opposition entre les candidats François Fillon et Emmanuel Macron face au reste des candidats. Les candidats Jean-Luc Mélenchon, Benoît Hamon, Marine Le Pen, les petits candidats Arthaud, Asselineau, et Poutou sont situés sur un même axes fort saturé, qui s’oppose à François Fillon également fort saturé et Emmanuel Macron de manière moins significative. Sur ce second axe, les classes sociales sont également nettement opposées lorsque nous observons les coefficients de saturation. En effet, les quartiers d’agriculteurs exploitants (CS1), d’artisans, de commerçants, de chefs d’entreprises (CS2), de cadres et de professions intellectuelles supérieures (CS3) sont nettement opposées à ceux où les professions intermédiaires (CS4), les employés (CS5) et les ouvriers (CS6) sont surreprésentés. Ceux sont regroupés sur un même axe identique à celui de Jean-Luc Mélenchon, Benoît Hamon et Marine Le Pen.
La cartographie des scores indique nettement le gradient Est-Ouest pour la première composante puisqu’elle oppose Emmanuel Macron et François Fillon au reste des candidats (voir Annexe \ref{scores1}). La seconde composante représente le caractère centre prériphérie, elle oppose Emmanuel Macron, Benoît Hamon et en moindre mesure Jean-Luc Mélenchon aux autres candidats, donnant la géographie centrée sur le carte de la seconde composante (voir Annexe \ref{scores2}).
Cette analyse en composantes principales, permet de se faire une idée de la géographie du vote de manière simplifiée. Il est par exemple possible de remarquer des liens entre les catégories sociales au sein des bureaux et certains candidats. Emmanuel Macron, semble liée aux bureaux avec de nombreuses professions intellectuelles supérieures, tandis que Benoit Hamon et Jean-Luc Mélenchon semblent liés aux quartiers des professions intermédiaires. De même les quartiers d’employés et d’ouvriers sont partagés entre l’extrême droite et l’extrême gauche. Enfin les bureaux d’artisans, de commerçants et de chefs d’entreprise sont proches de François Fillon. Toutefois ce ne sont là que des pistes qu’il s’agit d’explorer à l’aide des régressions linéaires multiples.
Résultats des différentes régressions
Pour chaque candidat, une régression linéaire multiple est effectuée. le choix des variables est réalisé sur base du tableau de corrélations entre les résultats des candidats, les catégories sociales, la population par âge et enfin la centralité (voir \ref{regmultiple}).
Il est important de garder à l’esprit qu’une corrélation élevée entre une variables indépendante et les résultats d’un candidat, signifie seulement que la variable indépendante est surreprésentée au sein du quartier où les votes pour le candidat sont plus élevés. Par exemple, les artisans, les commerçants et les chefs d’entreprises sont généralement plus présents dans les quartiers où le vote est plus élevé pour François Fillon. De cette manière nous évitons l’erreur écologique (voir \ref{erreurecol}). L’ensemble des régressions devrait permettre de déceler un effet de structure, à savoir si le vote pour un candidat est plus important au sein d’un bureau parce que le vote y est simplement plus élevé pour ce candidat dans une ou plusieurs classes sociales, ou si la classe sociale qui vote pour lui est surreprésentée mais ne vote pas plus pour lui qu’ailleurs. (Bussi M., 2012)
Lors de l’analyse du tableau de corrélation sur l’ensemble des variables socio-professionnelles entre elles, il apparaît que certaines classes socio-professionnelles sont fortement corrélées entre elles. Leur R2 dépasse les 50%, si elles sont introduites ensemble dans le modèle elles risquent de le fausser. Ce sont notamment les cadres et professions intellectuelles supérieures (CS3) qui sont fortement corrélés négativement aux employés (CS5) et ouvriers (CS6), celles-ci sont eux-mêmes corrélées entre elles. Autrement dit, lorsque beaucoup de cadres sont présents, il y a peu d’employés et d’ouvriers, et vice-versa mais en plus un grand nombre d’employés signifie un grand nombre d’ouvriers et réciproquement. Les professions intermédiaires (CS4) sont également corrélées négativement avec les sans emplois(CS8). Notons aussi que les retraités (CS7) sont fortement corrélées positivement avec les deux catégories d’âge les plus élevées (65-79 ans, 80 ans et plus). Dans la démarche de stepwise regression (voir \ref{regmultiple}), les variables sont sélectionnées selon le candidat, par exemple les cadres et professions intellectuelles supérieures représentent l’électorat d’Emmanuel Macron, les employés et ouvriers ne sont pas introduits dans la régression.
NB: Les agriculteurs exploitants au sein de Paris sont proche du 0\% et ne sont donc pas retenus dans les variables indépendantes.
% Fillon
\begin{table}[]
\small
\begin{tabular}{llllll}
term & estimate & std.error & statistic & p.value &
(Intercept) & -14.87 & 3.26 & -4.54 & 6.16e-06 & **
temp_cs$CS2 & 3.49 & 0.20 & 17.32 & 4.87e-58 & **
temp_cs$CS3 & 0.65 & 0.03 & 18.58 & 2.97e-65 & **
temp_cs$CS4 & -1.38 & 0.09 & -14.09 & 8.42e-41 & **
temp_cs$55-64 ans & 0.42 & 0.11 & 3.63 & 0.0002 & **
temp_cs$65-79 ans & 0.57 & 0.11 & 5.13 & 3.49e-07 & **
temp_cs$80 ans & 0.88 & 0.11 & 7.78 & 1.98e-14 & **
temp_cs$distance & 0.0029 & 0.00 & 17.15 & 4.07e-57 & **
\end{tabular} \
R2 ajusté: 0.7794, p-value: <2.2e-16
\caption{Coefficients de régression de François Fillon.}
\label{tab:reg_F}
\end{table}
% Hamon
\begin{table}[]
\small
\begin{tabular}{llllll}
term & estimate & std.error & statistic & p.value &
(Intercept) & -8.98 & 3.11 & -2.88 & 0.00 & **
temp_cs$CS2 & -0.49 & 0.07 & -6.83 & 1.49e-11 & **
temp_cs$CS4 & 0.40 & 0.03 & 12.36 & 1.82e-32 & **
temp_cs$CS5 & -0.11 & 0.02 & -4.25 & 2.28e-05 & **
temp_cs$CS6 & 0.39 & 0.04 & 9.76 & 1.81e-21 & **
temp_cs$CS7 & 0.17 & 0.04 & 4.10 & 4.48e-05 & **
temp_cs$18-24 ans & 0.13 & 0.04 & 3.34 & 0.00 & **
temp_cs$25-39 ans & 0.17 & 0.02 & 5.87 & 5.97e-09 & **
temp_cs$40-54 ans & 0.17 & 0.04 & 4.01 & 6.41e-05 & **
temp_cs$distance & -0.0007 & 4.98e-05 & -14.49 & 7.49e-43 & **
\end{tabular} \
R2 ajusté: 0.6818, p-value: <2.2e-16
\caption{Coefficients de régression de Benoît Hamon.}
\label{tab:reg_h}
\end{table}
% Le Pen
\begin{table}[]
\small
\begin{tabular}{llllll}
term & estimate & std.error & statistic & p.value &
(Intercept) & -2.18 & 0.62 & -3.48 & 0.00 & **
temp_cs$CS2 & -0.34 & 0.04 & -7.49 & 1.57e-13 & **
temp_cs$CS4 & 0.05 & 0.01 & 2.70 & 0.00 & **
temp_cs$CS6 & 0.16 & 0.02 & 7.50 & 1.55e-13 & **
temp_cs$CS7 & 0.09 & 0.01 & 6.30 & 4.52e-10 & **
temp_cs$40-54 ans & 0.08 & 0.01 & 4.81 & 1.73e-06 & **
temp_cs$55-64 ans & 0.12 & 0.02 & 5.32 & 1.31e-07 & **
temp_cs$distance & 0.0001 & 3.46e-05 & 3.78 & 0.00 & **
\end{tabular} \
R2 ajusté: 0.4096, p-value: <2.2e-16
\caption{Coefficients de régression de Marine Le Pen}
\label{tab:reg_l}
\end{table}
François Fillon
Benoît Hamon
Benoît Hamon connaît également un vote de classe (voir Table \ref{tab:reg_h}), les quartiers avec un grand nombre d’artisans, de commerçants et de chefs d’entreprise (CS2), de même pour ceux avec bon nombre d’employés (CS5) représentent ses moins bons scores. D’autre part les quartiers où les professions intermédiaires (CS4) et les retraités (CS7) sont surreprésentés ont effectué les meilleurs scores pour ce candidat toutes choses égales par ailleurs. Notons que contrairement à François Fillon (voir Table \ref{tab:reg_F}), son électorat est corrélé positivement et significativement aux quartiers où les âges de 18 à 54 ans sont fortement présents. La distance au centre joue un rôle négatif, indiquant le caractère central des quartiers ayant fortement voté pour lui.
Marine Le Pen
Le vote de Marine Le Pen (voir Table \ref{tab:reg_l}) est corrélé positivement aux quartiers ouvrier (CS6) et retraités (CS7), et de manière moins significative aux quartiers des professions intermédiaires. Son électorat ne provient pas des quartiers d’artisans, commerçants et chefs d’entreprise (CS2) puiqu’ils sont corrélés négativement avec la candidate et elle y réalise ses moins bons scores. L’âge est corrélé positivement de manière significative pour les catégories de 40 à 54 ans et plus fort pour les 55 à 64 ans. Enfin la distance au centre joue un rôle important dans le vote d’extrême droite, elle est corrélée positivement et significativement.
\pagebreak
% Macron
\begin{table}[]
\small
\begin{tabular}{llllll}
term & estimate & std.error & statistic & p.value &
(Intercept) & 21.67 & 1.77 & 12.24 & 6.38e-32 & **
temp_cs$CS2 & -0.42 & 0.11 & -3.85 & 0.00 & **
temp_cs$CS3 & 0.46 & 0.02 & 22.90 & 2.09e-91 & **
temp_cs$CS4 & 0.12 & 0.059 & 2.17 & 0.029 & *
temp_cs$18-24 ans & -0.03 & 0.041 & -0.77 & 0.43 &
temp_cs$25-39 ans & 0.04 & 0.02 & 1.74 & 0.08 & .
temp_cs$40-54 ans & -0.08 & 0.04 & -1.85 & 0.06 & .
temp_cs$distance & -0.0015 & 9.16e-05 & -16.66 & 2.22e-54 & **
\end{tabular} \
R2 ajusté: 0.6881, p-value:<2.2e-16
\caption{Coefficients de régression d’Emmanuel Macron.}
\label{tab:reg_MA}
\end{table}
% Regression Melenchon
\begin{table}[]
\small
\begin{tabular}{llllll}
term & estimate & std.error & statistic & p.value &
(Intercept) & -57.85 & 10.45 & -5.53 & 4.08e-08 & **
temp_cs$CS2 & -1.27 & 0.16 & -7.69 & 3.75e-14 & **
temp_cs$CS4 & 0.48 & 0.07 & 6.37 & 2.91e-10 & **
temp_cs$CS5 & 0.69 & 0.04 & 15.15 & 2.89e-46 & **
temp_cs$CS7 & 0.48 & 0.11 & 4.14 & 3.72e-05 & **
temp_cs$18-24 ans & 0.65 & 0.12 & 5.32 & 1.30e-07 & **
temp_cs$25-39 ans & 0.62 & 0.10 & 6.06 & 1.93e-09 & **
temp_cs$40-54 ans & 0.81 & 0.12 & 6.78 & 2.12e-11 & **
temp_cs$55-64 ans & 0.57 & 0.12 & 4.74 & 2.48e-06 & **
temp_cs$distance & -0.0008 & 0.00 & -7.70 & 3.66e-14 & **
\end{tabular} \
R2 ajusté: 0.7507, p-value: <2.2e-16
\caption{Coefficients de régression de Jean-Luc Mélenchon.}
\label{tab:reg_Me}
\end{table}
% Petits candidats
\begin{table}[]
\small
\begin{tabular}{llllll}
term & estimate & std.error & statistic & p.value &
(Intercept) & 0.31 & 0.30 & 1.03 & 0.30 &
temp_cs$CS2 & -0.14 & 0.01 & -8.60 & 3.49e-17 & **
temp_cs$CS4 & 0.051 & 0.00 & 6.60 & 6.90e-11 & **
temp_cs$CS5 & 0.07 & 0.00 & 17.51 & 3.73e-59 & **
temp_cs$CS7 & 0.01 & 0.00 & 3.48 & 0.00 & **
temp_cs$18-24 ans & 0.01 & 0.00 & 2.17 & 0.02 & *
temp_cs$distance & -6.53e-05 & 1.29e-05 & -5.04 & 5.46e-07 & ***
\end{tabular} \
R2 ajusté: 0.5226, p-value: <2.2e-16
\caption{Coefficients de régression des petits candidats.}
\label{tab:reg_Petits}
\end{table}
\clearpage
Emmanuel Macron
L’électorat d’Emmanuel Macron est un électorat issus des quartiers où les professions intellectuelles supérieures sont majoritaires (voir Table \ref{tab:reg_MA}) et moins significativement les quartiers avec un grand nombre de professions intermédiaires. L’âge ne semble pas impacté le vote pour Emmanuel Macron. La distance au centre est corrélée négativement et ce de manière significative, indiquant un vote plus important pour Emmanuel Macron dans les quartiers centraux.
Jean-Luc Mélenchon
Les résultats de la régression linéaire multiple de Jean-Luc Mélenchon (voir Table \ref{tab:reg_Me}) semblent être l’exact opposé de ceux pour François Fillon (voir Table \ref{tab:reg_F}) et est assez proche de celui de Benoît Hamon (voir Table \ref{tab:reg_h}). Les quartiers de surreprésentation des les classes aisées (CS2) mais également les professions intellectuelles supérieures (CS3), sont fortement corrélés négativement\footnote{Les CS3 sont corrélées négativement avec les CS5 et CS6.}, d’un autre côté les quartiers de professions intermédiaires (CS4), d’employés (CS5) et de retraités (CS7) sont corrélés positivement et significativement. Les quartiers ouvriers (CS6) sont le plus fortement corrélé, montrant leur importance décisive pour le vote de Jean-Luc Mélenchon. Ici, tout comme pour Benoît Hamon, la distance au centre est corrélée significativement mais cette fois elle est plus proche de la neutralité indiquant que les quartiers qui votent le plus fort pour Jean-Luc Mélenchon sont bien répartis sur le territoire.
Les petits candidats
La régression multiple des petits candidats (voir Table \ref{tab:reg_Petits}) avec les classes socio-professionnelles INSEE, l’âge et la centralité indique une corrélation positive avec les quartiers des professions intermédiaires, des employés (CS5) et des retraités (CS7). Les quartiers où ceux-ci sont les plus représentés sont ceux où les petits candidats font leurs meilleurs scores. A l’inverse, les quartiers où les artisans, commerçants et chefs d’entreprise (CS2) sont les plus présents, sont ceux qui représentent leurs moins bons scores. L’âge n’a presque pas d’importance, sauf pour les quartiers avec une surreprésentatino des 18-24 ans qui sont corrélés positivement de manière très peu significative. Enfin, comme pour Jean-Luc Mélenchon (voir Table \ref{tab:reg_Me}) et Benoît Hamon (voir Table \ref{tab:reg_h}), la distance au centre joue un rôle, mais elle est proche de zéro, indiquant un caractère ni central ni périphérique pour le vote des petits candidats.
Le second tour
La régression du vote pour Marine Le Pen lors de ce second tour indique une forte corrélation positive avec les quartiers d’employés, d’ouvriers, de retraités et de chômeurs. De plus la distance au centre garde un rôle significatif pour expliquer son électorat.
Emmanuel Macron présente une régression multiple du second tour beaucoup plus intéressante, son électorat est corrélé avec les quartiers de classes moyennes supérieures, mais aussi inférieures et de manière moins significative avec les quartiers où les classes aisées sont en surreprésentation. La distance au centre reste négative comme au premier tour.
Discussion
La littérature amène deux hypothèses majeures. La première pose que la classe sociale connaît un déclin dans l’explication du vote et est à présent accompagnée d’autres effets pour la compréhension complète de la décision électorale. La seconde indique que la scission des classes moyennes amène des phénomènes électoraux nouveaux.
Limites de l’étude
Avant d’interpréter les résultats, il est important de présenter les biais de notre analyse socio-géographique de Paris. Tout d’abord l’echelle intra-urbaine pose deux problèmes:
- Le découpage des bureaux de votes change parfois aléatoirement selon les années.
- La non-superposition des données sociales (généralement par communes) avec les bureaux de votes oblige une ventilation de données fragilisant ainsi la concordance. (Jardin, 2014)
Ajoutons que, comme expliqué dans la méthodologie (voir \ref{ventilation}), la mise en commun des données a provoqué la perte des données de 20 bureaux de vote de 2012 contenant des données sociologiques. Une demande des résultats directement à la ville de Paris et à l’échelle souhaitée aurait permis une meilleure mise en commun des données. Toujours au sein de la méthodologie, notre étude des classes pourrait être améliorée en ajoutant le niveau de diplôme qui semble être une variable importante au sein de la décision électorale ainsi que de l’abstention. (Rivière J, 2017)
La question de la pertinence des classes au sein de l’abstention est posée par Braconnier C.(2017). Celle-ci semble s’être propagée au sein de toutes les classes sociales puisqu’elle relève plus d’une revendication politique à présent. Nous n’avons pas développé l’abstention dans le cadre de ce travail car, pour fournir une analyse concrète et valable, il faudrait y consacrer l’entièreté d’un travail. Les cartes de l’abstention présentées servaient simplement à une meilleure visualisation. (Braconnier C., 2017)
Enfin, l’indicateur de centralité utilisé, à savoir la distance à Notre Dame, donne des corrélations très faibles, proches de 0, mais le caractère positif ou négatif de la relation ainsi que la significativité sont utilisées. Cette démarche peut être considérée comme une surinterprétation, mais les conclusions extraites des corrélations sont appuyées par la littérature.
Le vote de classe lors des élections présidentielles 2017
Afin d’observer si le vote de classe joue encore un rôle au sein des dernières élections présidentielles, il faut se pencher sur divers outils.
Tout d’abord l’échelle utilisée, à savoir l’échelle intra-urbaine, offre de nombreux avantages lors de l’observation du lien entre le vote et la classe sociale. Elle conserve le caractère hétérogène des quartiers. En effet, les disparités observées à l’échelle la plus fine constituent les différences visibles à l’échelle la plus large (régionale ou nationale par exemple). (Bussi M., 2001) De plus, une analyse à l’échelle intra-urbaine, évite le piège du spatialisme qui ne prend pas en compte les liens sociaux qui peuvent exister au sein de l’unité de recherche et permet de mettre en avant les effets de structure et de contextes. (Rivière J, 2012; Bussi M., 2012) Le risque majeur, lors d’une analyse de géographie électorale, consiste en l’erreur écologique. Effectivement, il convient de garder à l’esprit que ce sont des lieux qui sont étudiés et non pas des individus. (Beaugitte, 2013) Malgré tout, même si travailler à l’échelle intra-urbaine n’enlève pas l’erreur écologique, il en réduit le risque. Robinson J. (1950) considère qu’une taille plus fine d’entités spatiales, amène des relations visuelles et statistiques plus fiables. (Pion, 2009; Robinson, 1950) Enfin, un dernier effet s’observe à cette échelle, celui posé par Klatzmann J., à savoir l’influence de la décision électorale d’un quartier par les intéractions sociales avec un autre quartier. (David, 2011)
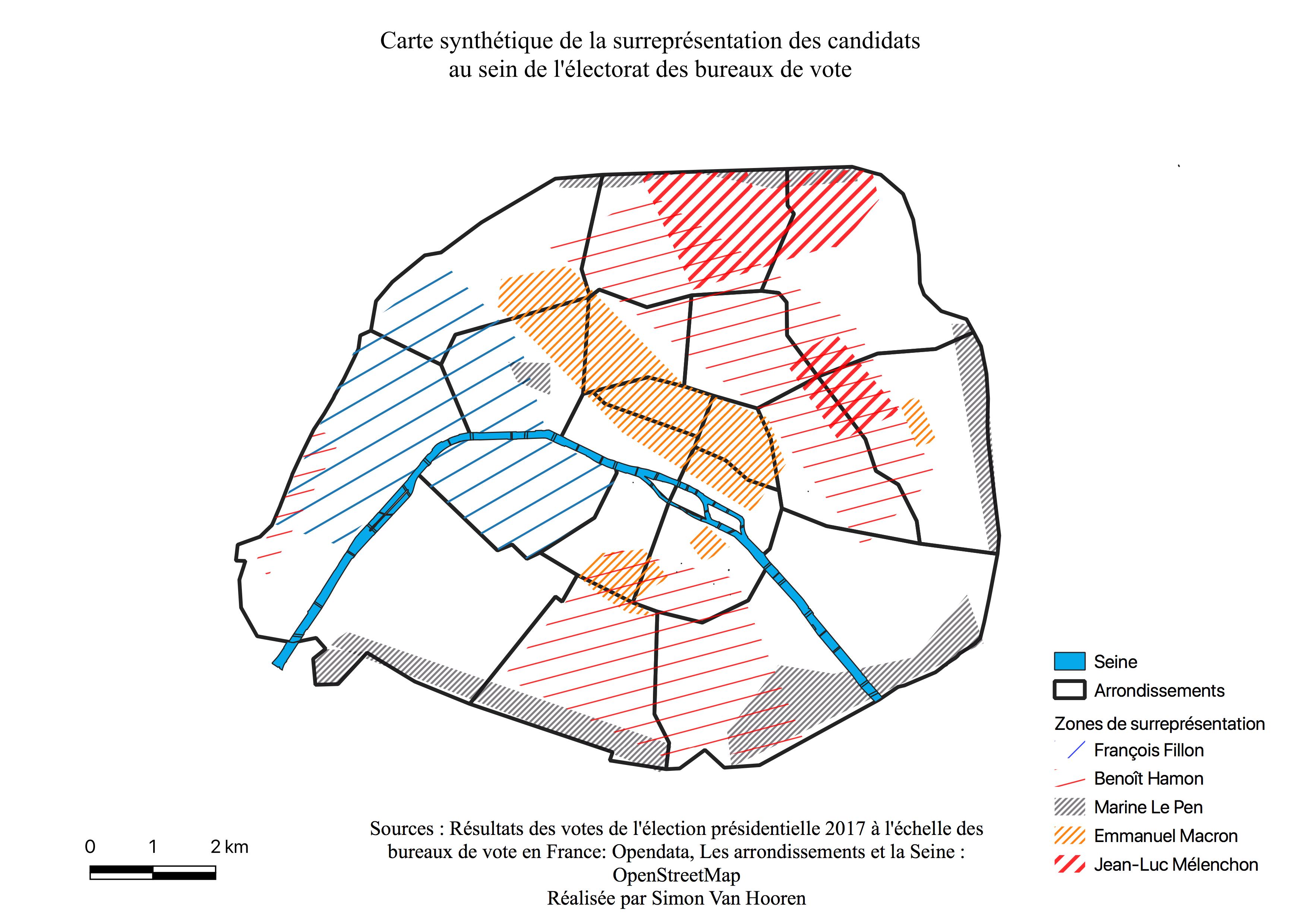
Une carte schématique de la surreprésentation de chacun des grands candidats (voir Figure \ref{synthese}) est produite sur base de leurs cartes respectives, afin de faciliter l’interprétation. L’Ouest des quartiers bourgeois historiques (voir Figure \ref{classessoc}, Annexe \ref{aises}) présente les meilleurs scores pour François Fillon. Le centre quant à lui est la zone des plus hauts résultats pour Emmanuel Macron, qui connait ses meilleurs scores aux quartiers de surreprésentation des cadres et professions intellectuelles supérieures (voir Annexe \ref{CS3}). Au Sud ainsi qu’à l’Est, entre la périphérie et la zone de survote pour Emmanuel Macron, sont disposés les votes les plus élevés pour Benoît Hamon, en lien cette fois-ci avec la carte des professions intermédiaires (voir Annexe \ref{CS4}). Les meilleurs résultats de Jean-Luc Mélenchon se situent dans les zones de quartiers populaires au Nord (voir Annexe \ref{popu}, et une petite partie de ce survote se situe au sein de l’électorat de Benoît Hamon. Enfin, Marine Le Pen est surreprésentée en périphérie. Notons que les électorats de Marine Le Pen (voir Figure \ref{C1L}) et Jean-Luc Mélenchon (voir Figure \ref{C1M}) mis en commun correspondent à la carte de la classes populaires à Paris (voir Annexe \ref{popu}).
Toutefois, comme le rappelle Rivière J.(2013), les cartes seules n’expliquent en rien les liens possibles entre le vote et les types de territoires; elles peuvent au mieux les suggérer. Les résultats empiriques servent à déduire les liens réels. (Rivière J., 2013) La suite du travail porte donc sur deux techniques statistiques et leurs résultats. Tout d’abord nous avons réalisé une Analyse en Composantes Principales sur l’ensemble des résultats des différents candidats avec les classes sociales en surimposition, ensuite nous avons effectué des régressions linéaires multiples entre les résultats électoraux et les données de recensement de la population afin de déceler les structures ainsi que le poids des catégories sociales dans les choix électoraux. Les différentes classes sociales ne connaissent pas les mêmes choix électoraux selon le territoire. (Bussi M., 2012)
L’Analyse en Composantes Principales réduit l’information selon des axes orthogonaux (voir Figure \ref{ACP1}) qui scindent les électorats de chaque candidat, mais aussi les classes sociales. Nous relevons les mêmes composantes que celles obtenues par Rivière J. (2017) sur l’ensemble des bureaux de vote en France, à savoir une opposition centre-périphérie pour la première. (Rivière J., 2017) Assurément, cette composante oppose François Fillon et Marine Le Pen à Benoît Hamon et Emmanuel Macron. Leurs régressions linéaires multiples indiquent une influence significative de la distance au centre. Par ailleurs, les variables supplémentaires surimposées dans le système d’axes de l’ACP, traduisent une opposition entre les classes moyennes (les cadres, les professions intellectuelles supérieures et les professions intermédiaires) face aux classes populaires telles que les employés, les sans emplois et les retraités. La deuxième composante, quant à elle, se traduit par l’opposition entre la droite-centriste et le reste du paysage électoral à savoir la gauche et les extrêmes. Effectivement Emmanuel Macron et Fillon sont opposés aux autres candidats, et ce, de manière suffisamment saturée. Les classes socio-professionnelles s’opposent ici selon un axe composé des classes aisées et des classes moyennes supérieures face aux classes moyennes inférieures, aux employés et aux ouvriers.
La régression linéaire multiple permet de déceler des liens entre le vote et des composantes sociales ou spatiales. Nous posons comme variables indépendantes les catégories socio-professionnelles, l’âge et la centralité. Le but n’est pas ici de déduire des comportements individuels mais bien de pouvoir catégoriser les différents quartiers. (Bussi M., 2012)
Le vote en faveur de Benoît Hamon (voir Figures \ref{C1H},\ref{synthese}) suit un gradient Est-Ouest avec ses meilleurs scores au sein des 10,11,18 et 20ème arrondissements, mais comme le montre la distribution de l’histogramme (voir Annexe \ref{H1H}), le plus grand nombre de quartiers ayant voté pour lui se situe dans ses bons scores (entre 8 à 10%). La régression (voir Table \ref{tab:reg_Me}) indique une corrélation positive avec les quartiers de professions intermédiaires, d’ouvriers et de chômeurs ainsi que ceux où les 25-54 ans sont surreprésentés. Comme expliqué auparavant, la distance au centre est corrélée significativement et négativement, indiquant que le vote de Benoît Hamon est rattaché à une certaine centralité. Le nouveau candidat du Parti Socialiste a subi la mauvaise popularité de François Hollande. (Tiberj, 2017) Rappelons qu’en 2012, François Hollande réalisait 55% à Paris. (Bussi M., 2012)
L’autre candidat de gauche, Jean-Luc Mélenchon, voit son vote évoluer selon le même gradient que Benoît Hamon, mais il est majoritairement sur les bordures du croissant (voir Figures \ref{C1M},\ref{synthese}). Leurs résultats sont proches géographiquement, mais Jean-Luc Mélenchon réalise des scores plus élevés (jusqu’à 35%). Il doit ses meilleurs résultats aux quartiers avec une surreprésentation d’employés (CS5) et d’ouvriers (CS6), comme le montre la régression (voir Table \ref{tab:reg_Me}) mais aussi la carte des classes populaires (voir Annexe \ref{popu}). Les quartiers nords de Paris et l’Ouest du 20ème arrondissement, lieux de ses meilleurs scores, sont effectivement les lieux de concentration des classes populaires.
Le gradient Est-Ouest de la gauche était déjà observé par différents auteurs depuis plusieurs années, tels que Bussi M. (2002) lors des élections de 1995, ou encore Gombin J. et Rivière J. (2014) plus récemment. (Bussi M, 2002; Rivière J, 2014)
La répartition du vote pour Emmanuel Macron présente ses meilleurs scores dans le centre de Paris (voir Figures \ref{C1EM},\ref{synthese}), mais les 9ème et le 17ème compte aussi un survote pour ce candidat. Notons que ce candidat est bien représenté au sein de la majorité des quartiers puisque son histogramme (voir Annexe \ref{H1EM}) indique une distribution assymétrique à droite, autrement dit, il comporte une majorité de hauts résultats. Son électorat semble correspondre à la carte des 25-39 ans (voir Annexe \ref{2539}) et celle des cadres et professions intellectuelles supérieures (voir Annexe \ref{CS3}). La régression multiple corrobore nos résultats avec ceux de Rivière J. (2017), et confirme le lien positif entre les quartiers où les classes moyennes supérieures sont surreprésentées et le vote pour Emmanuel Macron (voir Table \ref{tab:reg_MA}). (Rivière J., 2017) La distance au centre est également corrélée significativement et négativement, indiquant le caractère central de ses meilleurs scores, comme le montre la carte. Même si ses meilleurs scores se situent auprès de quartiers de surreprésentation des classes moyennes supérieures, l’histogramme (voir Annexe \ref{H1EM}) analysé infra, relève un caractère interclassiste que remarque Tiberj V. (2017). En effet, Emmanuel Macron tire parti d’un électorat évasé, il est mitigé auprès des centristes mais détient le même niveau de vote que Jean-Luc Mélenchon auprès des électeurs de gauche et possède un niveau assez élevé auprès des électeurs de droite. (Tiberj, 2017) Le reste de la régression appuie ces résultats, puisque les quartiers de professions intermédiaires lui sont également corrélées, mais moins significativement, ainsi que ceux où les tranches d’âge de 25 à 54 ans sont surreprésentées. Son histogramme, en lien avec la régression, s’interprète comme un survote pour Emmanuel Macron auprès des quartiers où les classe moyennes supérieures sont majoritaires, et les quartiers de surreprésentation des classes moyennes inférieures ont également voté pour lui mais moins fort (entre 20 et 32%). Malgré tout, Emmanuel Macron n’a pas conquis les quartiers d’employés et d’ouvriers puisque ceux-ci sont fortement corrélés négativement avec les cadres et professions intelectuelles supérieures (voir \ref{regmultiple}.
François Fillon possède un électorat (voir Figures \ref{C1F},\ref{synthese}) situé à l’Ouest dans les quartiers aisés de Paris, au sein des 6,7,8,16 et 17ème arrondissements, comme l’indique la carte de la répartition des classes sociales (voir Figure \ref{classessoc}). (Adoumie, 2013) L’histogramme (voir Annexe \ref{H1F}) indique que beaucoup de quartiers ont voté pour lui avec de faibles scores (entre 10 et 20%), justifiant l’agglomérat de quartiers en bleu foncé (39 à 53%) sur la carte. Les quartiers où il établit ses meilleurs scores, sont les zones historiques du vote pour la droite parlementaire, comme le confirme la forte corrélation positive (voir Table \ref{tab:reg_l}) avec les quartiers des classes aisées (CS2), nos résultats rejoignent ceux de Rivière J (2017) qui présente une corrélation de 0,95 entre les résultats de François Fillon en 2017 et ceux de Nicolas Sarkozy en 2012. La régression multiple indique que les bureaux où les personnes âgées de 55 à 80 ans et plus sont les plus représentées, sont fortement corrélés positivement. Ceci rejoint les résultats de Beaugitte L. et Colange C. (2013) qui expriment qu’au sein des beaux quartiers de Paris se retrouve une population majoritairement âgée, avec beaucoup de travailleurs indépendants, de cadres possédant des revenus élevés et qui sont propriétaires de leur logement. (Beaugitte, 2013) L’électorat de François Fillon évolue du centre vers les bordures Ouest de Paris intra-muros, comme le laissait présager la relation positive significative avec la distance au centre. Nous observons que ce candidat est fortement corrélé négativement avec les bureaux qui ont fortement voté pour Jean-Luc Mélenchon et Benoît Hamon, et qu’il est corrélé négativement avec les extrêmes gauche et droite (voir Annexe \ref{tab:table_corcand}), justifiant les zones de survote de François Fillon qui semblent limiter le vote de gauche et d’extrême droite, comme l’avançait Jardin A. (2014). De manière générale, l’électorat de François Fillon démontre bien, sur base de la relation entre les quartiers aisés et les résultats du candidat, que la bourgoisie est la dernière classe sociale mobilisée comme l’énonçaient Pinçon-Charlot M. et Pinçon M. (2003). (Pinçon-Charlot, 2003; Rivière J., 2012)
Enfin, la carte de l’électorat de Marine Le Pen ne pose pas le moindre doute quant à l’apport de la périphérie au sein des résultats (voir Figure \ref{C1L}, \ref{synthese}). Malgré tout, l’analyse par régression est nécessaire et vient confirmer la caractère périphérique du vote pour Marine Le Pen (voir table \ref{tab:reg_l}). La carte des résultats de la candidate comparée à celle des classes populaires (voir Annexe \ref{popu}) semble fort similaire en certains quartiers. La régression, comme Bussi M. (2012) l’avait remarqué à l’échelle des cantons, permet d’affirmer que Marine Le Pen tire bel et bien son électorat des quartiers présentant une majorité d’employés, d’ouvriers mais aussi de quartiers où les tranches d’âge de 40 à 64 ans sont surreprésentées (voir Annexes \ref{4054},\ref{5564}). (Bussi M., 2012) Cette géographie s’explique par la hausse des prix de l’immobilier au centre de Paris en partie due à la gentrification, qui pousse les populations des classes moyennes inférieures et des classes populaires vers les remparts de la ville voire dans la banlieue. (Fourquet, 2017) Le caractère périphérique du vote d’extrême droite peut être mis en lien avec la distance au centre. Celle-ci induit une diminution des interactions avec les autres classes sociales, diminuant l’effet de voisinage qui modifie les revendications d’une classe sociale. (Gombin J., 2013)
Reprenons l’Analyse en Composantes Principales (voir Figure \ref{ACP1}), celle-ci résume bien les positions des différents candidats et les relations qu’ils présentent entre eux. Elle relève l’opposition entre François Fillon et Jean-Luc Mélenchon; le premier tire son électorat des beaux quartiers (voir Table \ref{tab:reg_F}), tandis que Jean-Luc Mélenchon est surreprésenté auprès des quartiers populaires ainsi que des quartiers où les professions intermédiaires sont importantes (voir Table \ref{tab:reg_Me}). La relation importante relevée entre Benoît Hamon, Jean-Luc Mélenchon et les professions intermédiaires, s’observe bien sur le nouveau système d’axes, c’est moins vrai pour les ouvriers et les chômeurs. Historiquement, le choix des ouvriers se portait sur la gauche, comme le soulignaient déjà Lipset et Rokkan. (Tiberj, 2017) A présent cette relation n’est plus exclusive suite à la baisse d’encadrement ouvrier. Ils étaient représentés par le parti socialiste. Maintenant, plus aucun parti ne leur est propre, les obligeant à se redistribuer au sein du paysage électoral. (Van Hamme G., 2012) De manière générale, les classes populaires sont déstabilisées et désorganisées. (Jardin A., 2014) Elles se sentent moins représentées et choisissent l’abstention, la gauche ou les extrêmes. (Gombin J, 2013) Nos résultats confirment que les extrêmes gauche et droite, représentées par Marine Le Pen et les petits candidats (voir Tables \ref{tab:reg_l},\ref{tab:reg_Petits}), sont corrélées significativement avec les employés et ouvriers. Enfin Emmanuel Macron, situé seul dans un cadran avec les cadres et les professions intellectuelles supérieures, montre non seulement l’importance de ces quartiers pour son électorat, mais aussi la distinction avec le reste des candidats. Il n’est affilié ni à l’électorat de droite ni à la gauche, ni aux extrêmes.
Par ailleurs, le second tour des élections n’est pas probant pour l’explication du vote de classe, les électeurs n’ont le choix qu’entre les deux candidats et l’abstention. C’est ce que nous observons avec les régressions des deux candidats, le spectre d’Emmanuel Macron s’est élargi. Il est à présent corrélé positivement aux artisans, commerçants et chefs d’entreprise de manière relativement significative, indiquant la redistribution de l’électorat de François Fillon. De la même manière, les quartiers où beaucoup de professions intermédiaires sont présentes, ont voté pour lui de manière significative, indiquant cette fois la récupération de l’électorat de Benoît Hamon et Jean-Luc Mélenchon. Marine Le Pen quant à elle, conserve le même électorat, c’est à dire majoritairement les quartiers où les classes populaires sont surreprésentées. Enfin, notre carte de l’abstention du second tour (voir Annexe \ref{abs2}) relève un plus haut taux d’abstention auprès de l’Ouest de Paris, zone des quartiers bourgeois, rejoignant les résultats de Braconnier C. qui a démontré que l’abstention à Paris, habituellement attribuée aux classes populaires, est attribuée aux classes aisées lors de ce second tour. (Braconnier C., 2017) Ces exemples justifient notre intérêt pour le premier scrutin comme seule base explicative du vote de classe.
A l’aide de nos résultats nous avons démontré que la classe sociale garde tout de même un rôle important au sein de la désicion électorale. La bourgoisie reste la classe la plus mobilisée pour ses intérêts, les classes populaires choisissent encore majoritairement la gauche et les extrêmes, enfin les classes intermédiaires sont partagées entre le vote des classes aisées et celui des classes populaires. Nos résultats rejoignent ceux de Gana A. en Tunisie, qui affirme que les inégalités sociales et territoriales restent une clef de compréhension des comportements électoraux. Nous venons de le vérifier pour les élections présidentielles de 2017 à Paris intra-muros, du moins à l’échelle intra-urbaine. (Gana et al., 2012)
Malgré tout, l’analyse des cartes de résidus de la régression linéaire multiple pose question. Effectivement, en se basant sur la carte de synthèse des résidus (voir Figure \ref{synthres}), nous observons que le vote est encore plus ofrt qu’attendu par le modèle pour les grands candidats que ce qui était expliqué par le modèle.
Ces écarts indiquent que le vote de classe joue encore un rôle important mais qu’il n’est plus le seul à expliquer les choix électoraux. D’autres phénomènes entrent en jeu, pour beaucoup l’effet de voisinage est un élément important. Celui-ci peut s’observer dans des quartiers où une classe sociale est surreprésentée, mais qui vote différemment de ce qui est attendu, suite au voisinage d’un quartier de composition sociologique différente. Comme l’avait démontré Klatzmann J. avec les ouvriers dans un univers bourgeois qui ont tendance à voter libéral. (David, 2011)
Le vote scindé des classes intermédiaires
La classe moyenne connaît une division en son sein, celle-ci est dûe à la société actuelle de post-abondance comme l’expliquait Chauvel L. (2006). Cette division interne s’accompagne de l’individualisation de la classe laissant ainsi présager un vote scindé au sein de la classe moyenne. (Garnier, 2010; Pinçon-Charlot, 2003; Chauvel L. 2006) Afin d’analyser le vote de la classe intermédiaire, il importe de la définir. Comme l’explique Van Hamme G., les limites de cette classe son incertaines, elle se situe entre la bourgeoisie qui détient les moyens de productions, et les salariés de l’industrie et des services qui effectuent les tâches d’exécution. (Van Hamme, 2012) C’est sur base de cette définition que sont choisies les classes soiales au sein de ce travail :
- Les classes aisées sont les artisans, commerçants et chefs d’entreprise.
- Les classes populaires sont les employés, les ouvriers et les chômeurs.
- Les agriculteurs exploitants, extrêmement minimes voir nuls au sein des données de Paris intra-muros ne sont pas pris en compte.
- Les retraités n’appartenant à aucune classe ne sont pas répertoriés. Remarquons toutefois le rôle important des quartiers où ils sont surreprésentés à Paris intra-muros, dans l’électorat de François Fillon (voir Table \ref{regf})
Ainsi, il ne reste plus que les les professions intermédiaires (CS4), les cadres et les professions intellectuelles supérieures (CS3) qui sont attribués à la classe moyenne.
A nouveau, observons l’Analyse en Composantes Principales (voir Figure \ref{ACP1}). Au sein de l’axe centre-périphérie les classes moyennes inférieures et supérieures se positionnent du même côté, ce qui s’observe sur la carte des classes intermédiaires (voir Figure \ref{classmoy}). Elles sont surreprésentées au sein du centre et les seuls endroits où leur nombre décroit sont les bordures, le Nord-Est et l’Ouest bourgeois lieu de surreprésentation des classes aisées. A l’inverse, sur l’axe droite centriste - gauche et extrêmes, les classes moyennes supérieures sont en opposition avec les classes moyennes inférieures. Les premières sont liées à Emmanuel Macron, tandis que les secondes sont liées à Benoît Hamon, Mélenchon et en moindre mesure Marine Le Pen.
Afin de vérifier la véracité de ce que pose l’Analyse en Composantes Principales nous observons les \textbf{régressions}. Comme observé auparavant, le vote pour Emmanuel Macron est fortement corréle positivement avec les bureaux où les classes moyennes supérieures et les 25-39 ans sont surreprésentées (voir Table \ref{regM}) rejoignant les résultats de Rivière J. (2017). Il observe l’émergence du vote pour Emmanuel Macron à l’intérieur des quartiers regroupant les personnes détenant de fort capitaux, locataires du parc privé et fortement diplômés, mais plus jeunes que dans les beaux quartiers qui préfèrent François Fillon. (Rivière J., 2017) D’autre part nos résultats se croisent à nouveau sur la relation positive entre les quartiers de survote pour Emmanuel Macron et ceux de François Fillon et Benoît Hamon, quoique cette corrélation ne soit pas très élevée (voir Annexe \ref{tab:table_cor}).
\begin{table}[] \centering \begin{tabular}{|l|l|l|} \hline & CS3 & CS4 \ \hline François Fillon & + * & - *** \ \hline Benoît Hamon & - *** & + *** \ \hline Marine Le Pen & - *** & + ** \ \hline Emmanuel Macron & + *** & + * \ \hline Jean-Luc Mélenchon & - *** & + *** \ \hline Petits candidats & - *** & +* \ \hline \end{tabular} \caption{Récapitulatif des régressions linéaires multiples des CS3 et CS4} \label{tab:recapreg} \end{table}
Comme nous pouvons l’observer sur la table récapitulative de corrélation entre les candidats et les classes moyennes supérieures et inférieures (voir Figure \ref{tab:recapreg}), les quartiers dominés par les cadres et professions intellectuelles supérieures sont des lieux de survote pour François Fillon et Emmanuel Macron, mais également des lieux de moins bons scores pour les autres candidats. Cela s’explique par le capital économique qui est un sujet important pour ces quartiers où les personnes à plus hauts revenus sont surreprésentées. A l’inverse les bureaux où les professions intermédiaires sont majoritaires, Benoît Hamon, Jean-Luc Mélenchon et les petits candidats réalisent leurs meilleurs scores. Ces mêmes quartiers sont, en moindre mesure, des zones de bons scores pour Marine Le Pen et Emmanuel Macron. Enfin ce sont les quartiers où François Fillon réalise ses moins bons scores.
Les résidus des régressions nous indiquent un effet de voisinage, comme expliqué plus haut. Intéressons-nous aux différences entre le vote théorique produit par le modèle et le vote réel observé dans les scrutins. Prenons par exemple le Nord-Ouest du 14ème arrondissement, zone de surreprésentation des cadres et professions intellectuelles (voir Annexe \ref{CS3}). Or Benoît Hamon y fait de meilleurs scores que ce que le modèle a prédit (voir Annexe \ref{residH}, Figure \ref{synthres}). Ces résultats permettent de supposer que les classes moyennes supérieures qui se sont installées dans cet arrondissement lors d’une vague de gentrification (voir Figure \ref{gentrif}), ont été amenées à cotoyer les habitants des quartiers moins aisés, influençant leur décision de classe. (Clerval A., 2008)
Un autre exemple probant si situe dans le Nord-Est du 12ème arrondissement. En bordure nous retrouvons une zone de surreprésentation des professions intermédiaires (voir Annexe \ref{CS4}). Seulement ces quartiers sont entourés d’une zone où les classe moyennes supérieures sont majoritaires, les amenant à voter plus qu’attendu pour Emmanuel Macron et Marine Le Pen alors que le modèle théorique leur donnait un vote pour Benoit Hamon, Jean-Luc Mélenchon.
Grâce à ces résultats nous sommes en mesure de dire que les quartiers où les classes intermédiaires sont surreprésentées ne votent pas de manière homogène. Par conséquent une scission des classes intermédiaires en deux sous-classes, à savoir celles pourvues d’un capital économique, et celles pourvues d’un capital intellectuel, permet de justifier les nouveaux choix de ces quartiers. (Gombin J., 2013) Les premières votent pour la droite ou la droite centriste qui défend leurs intérêts économiques, les secondes se retrouvent dans les électorats de gauche ou d’extrême droite. Ces quartiers différenciés des classes moyennes, semblent être liés aux avancées successives de la gentrification (voir Figure \ref{gentrif}). Une étude de socio-géographie liée à de la géographie urbaine, comme Mansley E. et Demsar U. (2015) l’ont fait pour Tel Aviv, pourrait éclairer les dynamiques en place. (Mansley, 2015)
Conclusion
Les liens entre le comportement électoral et la répartition spatiale des classes sociales sont, à l’échelle intra-urbaine, le vote de classe et l’effet de voisinage. Effectivement, comme nos résultats l’ont montré, la classe sociale joue un rôle non-négligeable dans la compréhension de la décision électorale, mais il n’est plus le seul explicatif. L’effet de voisinage s’ajoute au vote de classe pour expliquer les quelques écarts entre le vote théorique que nous avons réalisé et le vote réel. Nous avons également montré que les quartiers dominés par les classes intermédiaires votent différemment et ne revendiquent pas la même idéologie partisane. La nouvelle classe moyenne se scinde en deux, avec les quartiers surreprésentés par les professions intermédiaires qui ont tendance à voter pour des candidats de la gauche ou des extrêmes en moindre mesure, et les quartiers dominés par les cadres, les professions intellectuelles supérieures, qui choisissent des candidats de droite. Enfin l’échelle intra-urbaine est la plus proche de l’individu, bien qu’elle ne montre que le choix électoral des quartiers. Elle pourrait encore être améliorée à l’aide de la géographie urbaine et les liens avec les dynamiques de gentrification.
Références
(APUR) Atelier Parisien d’Urbanisme. Les classes moyennes et le logement à Paris. 2006.
Adoumié Vincent. Géographie de la France. 2013. Paris , Hachette.
Beauguitte Laurent, Colange Céline. Analyser les comportements électoraux à l’échelle du bureau de vote. 2013.
Braconnier Céline, Coulmont Baptiste, Dormagen Jean-Yves. Toujours pas de chrysan- thèmes pour les variables lourdes de la participation électorale : Chute de la participation et augmentation des inégalites électorales au printemps 2017 // Revue française de science politique. 2017. 67, 6. 1023.
Braconnier Céline, Dormagen Jean-Yves. Une démocratie de l’abstention. Retour sur le non-vote et ses conséquences politiques lors des scrutins municipaux et européens de 2014 // Hérodote. 2014. 154, 3. 42.
Braconnier Céline, Lehingue Patrick. Une autre sociologie du vote, Les électeurs dans leurs contextes : bilan critique et perspectives. 2010. Laboratoire d’études juridiques et poli- tiques.
Bréchon P. Les surprises de l’élection présidentielle de 2017. 2017.
Bussi Michel, Fourquet Jérôme, Colange Céline. Analyse et compréhension du vote lors des élections présidentielles de 2012 : L’apport de la géographie électorale // Revue française de science politique. 2012. 62, 5. 941.
Bussi Michel, Freire-Diaz Sylviano. Les nouvelles spatialités des comportements électoraux français. L’exemple des élections présidentielles 1981-1995. 2002.
Charney Igal, Malkinson Dan. Between electoral and urban geography : Voting patterns and socio-spatial dynamics in Tel Aviv // Applied Geography. III 2015. 58. 1–6.
Chauvel Louis. Les classes moyennes à la dérive. 2006. Seuil.
Clark Thierry, Lipset Seymour. The breakown of class politics : A debate on post-industrial stratification. 2001. Johns Hopkins University Press.
Clerval Anne. La gentrification à Paris intra-muros : dynamiques spatiales, rapports sociaux et politiques publiques. 2008.
Clerval Anne. Paris sans le peuple : La gentrification de la capitale. 2013. La découverte. David Quentin, Van Hamme Gilles. Pillars and electoral behavior in Belgium : The neigh-borhood effect revisited // Political Geography. VI 2011. 30, 5. 250–262.
De Graaf Dirk, Nieuwbeerta Paul. The effects of class voting post-war western indistrualized countries // European Sociological Review. 2000.59
Ehrhard Thomas. La difficile condition des “petits candidats”. 2017.
Fourquet Jérôme. Un nouveau clivage : Perdants versus gagnants de la mondialisation Commentaire. 2017. Numéro158, 2. 265.
Franklin Mark. The decline of Cleavage Politics. 1992. Cambridge University Press.
Gana Alia, Hamme Gilles Van, Rebah Maher Ben. Géographie électorale et disparités socio- territoriales : les enseignements des élections pour l’assemblée constituante en Tunisie // L’Espace Politique. XI 2012. 18.
Garnier Jean-Pierre. Une violence éminemment contemporaine : Essai sur la ville ville, La petit bourgeoisie intellectuelle et l’effacement des classes populaires. 2010. Argone.
Girault Frédéric, Bussi Michel. Les organisations spatiales de la ségrégation urbaine : l’exemple des comportements électoraux // Espace géographique. 2001. 30, 2. 152.
Gombin Joël, Rivière Jean. Éléments quantitatifs sur la dimension spatiale des effets électo- raux des inégalités sociales dans les mondes périurbains français (2007-2012). 2013.
Gombin Joël, Rivière Jean. Vers des convergences interdisciplinaires dans le champ des études électorales ? VII 2014. ##### Hamon Francis, Troper Michel. Droit constitutionnel - 39ème édition. 2018. (Manuels).
James Gareth, Witten Daniela, Hastie Trevor, Tibshirani Robert. An Introduction to Sta- tistical Learning. 103. New York, NY : Springer New York, 2013. (Springer Texts in Statistics).
Jardin Antoine. Le vote intermittent - Comment les ségrégations urbaines influencent-elles les comportements électoraux en Ile-de-France ? // L’Espace Politique. VII 2014. 23.
Klatzmann Joseph. Population ouvrière et vote communiste à Paris // Actes de la recherche en sciences sociales. 1981. 36, 1. 83–86.
Lazarsfeld Paul, Berelson Bernard, Gaudet Hazel. The people’s choice. 1944. Columbia University Press.
Le monde AFP. Qui sont les six “petits” candidats ? IV 2017.
Ley David. The new middle class and the remaking of the Central city. 1996. Oxford Uni-
versity Press.
Mansley Ewan, Demsar Urska. Space matters : Geographic variability of electoral turnout determinants in the 2012 London mayoral election // Electoral Studies. 2015. 40. 322–334.
Pinçon-Charlot Monique, Pinçon Michel. Sociologie de la bourgeoisie. 2003. La découverte. Pion Geoffrey. Géographie des comportements électoraux protestataires en Wallonie : une approche infra-communale à Charleroi et Mons // Belgeo. 2009. 2. 153–168. 60
Rivière Jean. Vote et géographie des inégalités sociales : Paris et sa petite couronne. 2012. Rivière Jean. Sous les cartes, les habitants : La diversité du vote des périurbains en 2012 Esprit. 2013. Mars/Avril, 3. 34.
Rivière Jean. Les divisions sociales des métropoles françaises et leurs effets électoraux Une comparaison des scrutins municipaux de 2008. 2014.
Rivière Jean. L’espace électoral des grandes villes françaises : Votes et structures sociales intra-urbaineslors du scrutin présidentiel de 2017 // Revue française de science politique. 2017. 67, 6. 1041.
Robinson William. Ecological Correlations and the Behavior of Individuals. 1950.
Tiberj Vincent. Running to stand still, Le clivage gauche/droite en 2017. 2017.
Van Criekingen Mathieu. Méthodes Quantitatives et Modélisation en Géographie. 2018.
Van Hamme Gilles. Social classes and political behaviours : Directions for a geographical analysis // Geoforum. VI 2012. 43, 4. 772–783.
Van Hamme Gilles, Van Criekingen Mathieu. Recompositions de classes et clivages poli- tiques au sein des espaces urbains // Espace et rapports de domination, Rennes : Presses Universitaires de Rennes, pp. 189 - 200. 2015. 9.
Annexes : Histogrammes
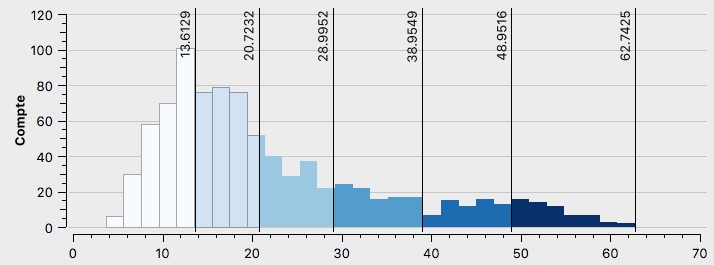
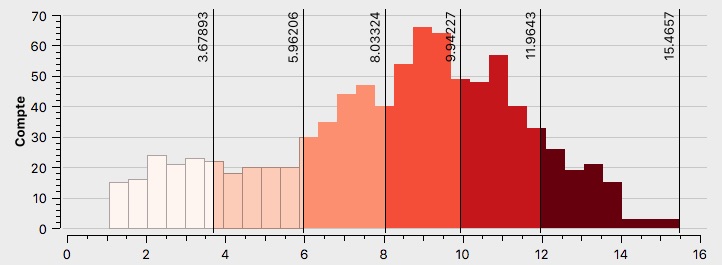
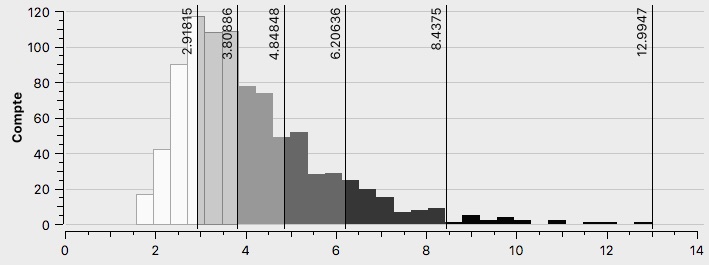
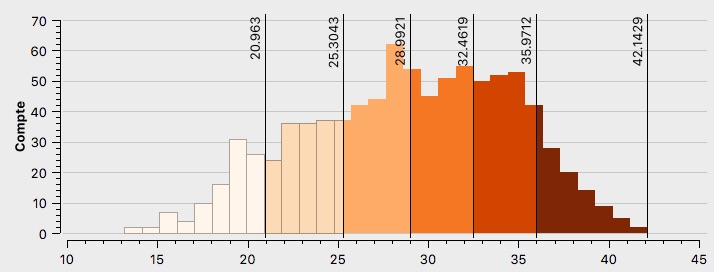
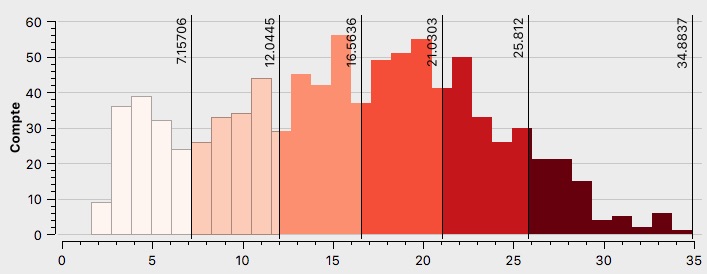
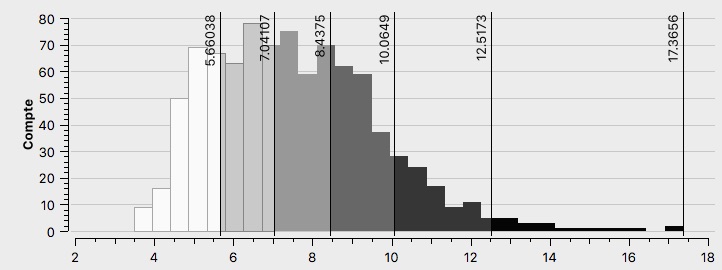
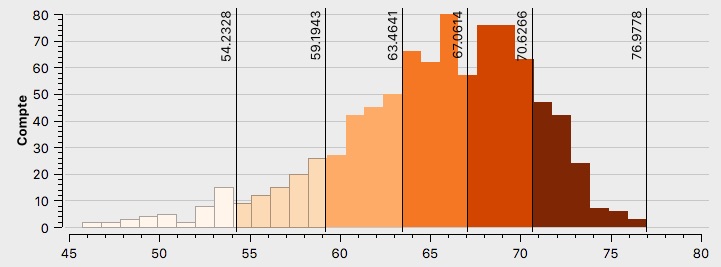
Annexes : Cartes